Navegador de Scraping y Cloudflare
Este documento técnico explica cómo usar las herramientas Scrapeless Scraping Browser y Scrapeless Web Unlocker para manejar varios desafíos de seguridad implementados por Cloudflare. Las características clave incluyen eludir el Desafío JS de Cloudflare, Cloudflare Turnstile, y ejecutar el renderizado de JavaScript para acceder al contenido protegido por Cloudflare. Este documento proporcionará conocimientos relevantes, introducción a las funciones, pasos operativos y explicaciones de ejemplos de código.
Comprender los desafíos y las capas de seguridad de Cloudflare
Cloudflare, un popular servicio de seguridad y rendimiento web, protege principalmente los sitios web del tráfico malicioso o inesperado, como bots y escáneres. Para ello, Cloudflare implementa varios mecanismos de detección y defensa, incluyendo, pero no limitándose a:
1. Desafío JS (Desafío JavaScript): Requiere que el navegador del visitante ejecute código JavaScript específico para verificar que se trata de un entorno de navegador legítimo con funcionalidad estándar.
2. Alternativa CAPTCHA Turnstile: Un mecanismo de verificación menos intrusivo para distinguir entre usuarios humanos y bots.
3. Huellas dactilares del navegador: Recopila y analiza las características técnicas del navegador y el dispositivo (por ejemplo, User-Agent, resolución de pantalla, fuentes instaladas, complementos) para identificar y rastrear a los visitantes.
4. Limitación de velocidad: Monitoriza y limita el número de solicitudes de una sola fuente (por ejemplo, dirección IP) dentro de un tiempo específico para evitar ataques de fuerza bruta o abuso de recursos.
Estas capas de seguridad impiden que las bibliotecas de solicitudes HTTP básicas, los scripts simples o los navegadores headless mal configurados accedan a sitios web protegidos por Cloudflare, lo que resulta en fallos de verificación y denegación de acceso.
Diferencias entre el desafío JS de Cloudflare y otros desafíos
La singularidad del Desafío JS de Cloudflare radica en su método de verificación. No solo requiere que los usuarios completen una tarea interactiva simple (por ejemplo, reconocimiento de imágenes); exige que el entorno del cliente (navegador) analice y ejecute correctamente el código JavaScript generado dinámicamente, a menudo ofuscado, de Cloudflare. Este código realiza comprobaciones de entorno, tareas computacionalmente intensivas u otra lógica para verificar las capacidades de comportamiento complejo del cliente, imitando un navegador real.
Superar con éxito el Desafío JS implica generar un token de autorización válido (generalmente en forma de una cookie cf_clearance). Este token demuestra que el cliente superó la verificación de la capacidad de ejecución de JavaScript. Muchas herramientas de automatización carecen de un motor de ejecución de JavaScript completo y de una simulación realista del entorno del navegador, por lo que fallan en tales desafíos.
Eludir el desafío JS de Cloudflare usando Scrapeless Scraping Browser
Scrapeless Scraping Browser está diseñado para manejar medidas de protección de sitios web complejas, incluyendo el Desafío JS de Cloudflare.
Pasos y ejemplo de código
Configuración del entorno
Crear una carpeta de proyecto
Crea una nueva carpeta para el proyecto, por ejemplo: scrapeless-bypass.
Navega a la carpeta en tu terminal:
cd path/to/scrapeless-bypassInicializar el proyecto Node.js
Ejecuta el siguiente comando para crear un archivo package.json:
npm init -yInstalar las dependencias necesarias
Instala Puppeteer-core, que permite la conexión remota a instancias del navegador:
npm install puppeteer-coreSi Puppeteer aún no está instalado en tu sistema, instala la versión completa:
npm install puppeteer puppeteer-coreObtener y configurar tu clave API de Scrapeless.
Conectar y asegurar que el CAPTCHA se resuelve correctamente
Scrapeless detecta y resuelve automáticamente los CAPTCHA al conectarse al navegador para acceder al sitio web de destino. Sin embargo, debemos asegurarnos de que el CAPTCHA se resuelve correctamente. Scrapeless Scraping Browser extiende el CDP (Chrome DevTools Protocol) estándar con un potente conjunto de capacidades personalizadas. El estado del solucionador de CAPTCHA se puede observar directamente comprobando los resultados devueltos de la API de CDP:
Captcha.detected: CAPTCHA detectadoCaptcha.solveFinished: CAPTCHA resuelto correctamenteCaptcha.solveFailed: Error al resolver el CAPTCHA
import puppeteer from "puppeteer-core";
import EventEmitter from 'events';
const emitter = new EventEmitter()
const scrapelessUrl = 'wss://browser.scrapeless.com/api/v2/browser?token=your_api_key&sessionTTL=180&proxyCountry=ANY';
export async function example(url) {
const browser = await puppeteer.connect({
browserWSEndpoint: scrapelessUrl,
defaultViewport: null
});
console.log("Verbonden met Scrapeless browser");
try {
const page = await browser.newPage();
// Listen for captcha events
console.debug("addCaptchaListener: Start listening for captcha events");
await addCaptchaListener(page);
console.log("Navigated to URL:", url);
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 30000 });
console.log("onCaptchaFinished: Waiting for captcha solving to finish...");
await onCaptchaFinished()
// Screenshot for debugging
console.debug("Taking screenshot of the final page...");
await page.screenshot({ path: 'screenshot.png', fullPage: true });
} catch (error) {
console.error(error);
} finally {
await browser.close();
console.log("Browser closed");
}
}
async function addCaptchaListener(page) {
const client = await page.createCDPSession();
client.on("Captcha.detected", (msg) => {
console.debug("Captcha.detected: ", msg);
});
client.on("Captcha.solveFinished", async (msg) => {
console.debug("Captcha.solveFinished: ", msg);
emitter.emit("Captcha.solveFinished", msg);
client.removeAllListeners()
});
}
async function onCaptchaFinished(timeout = 60_000) {
return Promise.race([
new Promise((resolve) => {
emitter.on("Captcha.solveFinished", (msg) => {
resolve(msg);
});
}),
new Promise((_, reject) => setTimeout(() => reject('Timeout'), timeout))
])
}Este flujo de trabajo de ejemplo accede al sitio web de destino y confirma que el CAPTCHA se ha resuelto correctamente escuchando el evento Captcha.solveFinished de CDP. Finalmente, captura una captura de pantalla de la página para su verificación.
Este ejemplo define dos métodos principales:
addCaptchaListener: para escuchar eventos CAPTCHA dentro de la sesión del navegadoronCaptchaFinished: para esperar hasta que se haya resuelto el CAPTCHA
El código de ejemplo anterior se puede usar para escuchar eventos CDP para tres tipos comunes de CAPTCHA que se analizan en este artículo: reCAPTCHA v2, Cloudflare Turnstile y Cloudflare 5s Challenge.
Tenga en cuenta que el Desafío Cloudflare 5s es algo especial. A veces no desencadena un desafío real, y confiar únicamente en la detección de eventos CDP para el éxito puede provocar tiempos de espera. Por lo tanto, esperar a que aparezca un elemento específico en la página después del desafío es una solución más estable.
Conexión al WebSocket sin servidor de Scrapeless Browser
Scrapeless proporciona una conexión WebSocket, que permite a Puppeteer interactuar directamente con el navegador sin cabeza, eludiendo los desafíos de Cloudflare.
La dirección de conexión WebSocket completa:
wss://browser.scrapeless.com/api/v2/browser?token=APIKey&sessionTTL=180&proxyCountry=ANYEjemplo de código: Eludir el desafío de Cloudflare
Solo necesitamos el siguiente código para conectarnos al servicio sin servidor de Scrapeless.
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com/api/v2';
const query = new URLSearchParams({
token: API_KEY,
sessionTTL: '180', // El ciclo de vida de una sesión del navegador, en segundos
proxyCountry: 'GB', // País del agente
proxySessionId: 'test_session_id', // El ID de sesión del proxy se utiliza para mantener la IP del proxy sin cambios. El tiempo de sesión es de 3 minutos por defecto, según la configuración de proxySessionDuration.
proxySessionDuration: '5' // Tiempo de sesión del agente, unidad minutos
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')Acceder a sitios web protegidos por Cloudflare y verificación de captura de pantalla
A continuación, utilizamos scrapeless browserless para acceder directamente al sitio de prueba de desafío de cloudflare y añadimos una captura de pantalla, lo que permite la verificación visual. Antes de tomar la captura de pantalla, tenga en cuenta que debe usar waitForSelector para esperar elementos en la página, asegurando que el desafío de Cloudflare se haya superado correctamente.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// Esperando elementos en la página del sitio, asegurando que el desafío de Cloudflare se haya superado correctamente.
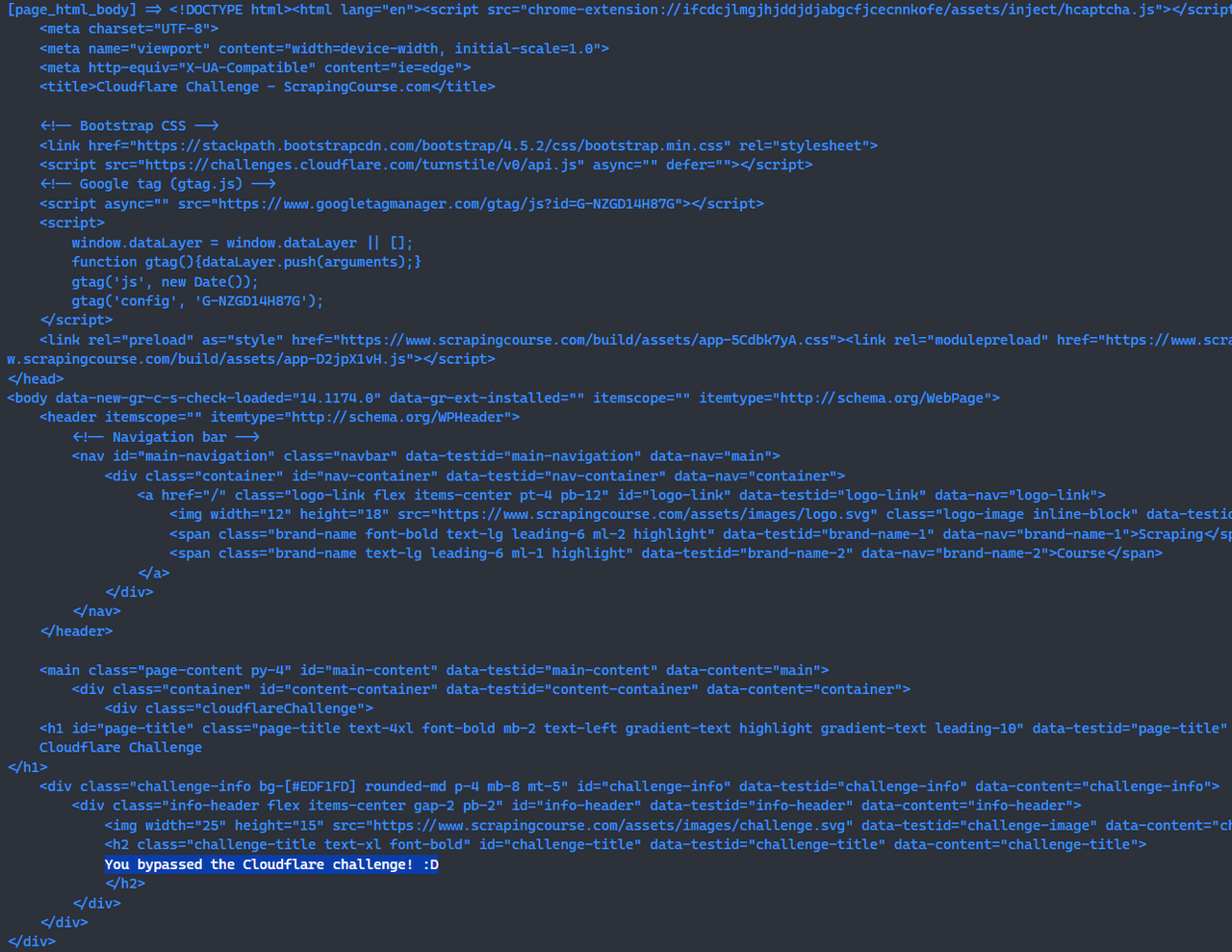
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
await page.screenshot({path: 'challenge-bypass.png'});En este punto, ha superado el desafío de Cloudflare usando Scrapeless Browserless.

Recuperar la cookie cf_clearance y el encabezado
Después de superar el desafío de Cloudflare, puede recuperar los encabezados de la solicitud y la cookie cf_clearance de la página correcta.
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueHabilitar la interceptación de solicitudes para capturar los encabezados de las solicitudes y hacer coincidir las solicitudes de página después del desafío de Cloudflare.
await page.setRequestInterception(true);
page.on('request', request => {
// Hacer coincidir las solicitudes de página después del desafío de cloudflare
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});Eludir Cloudflare Turnstile usando Scrapeless Scraping Browser
Scrapeless Scraping Browser también maneja los desafíos de Cloudflare Turnstile.
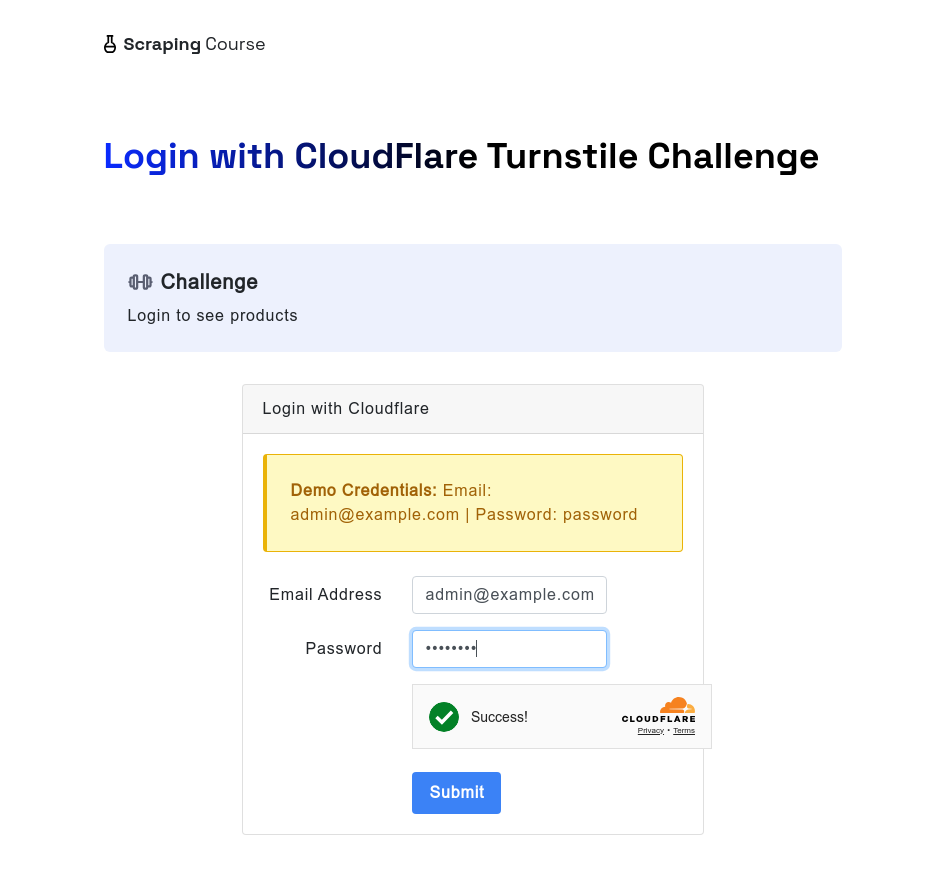
De manera similar, cuando se enfrenta a Cloudflare Turnstile, el navegador de scraping sin servidor aún puede manejarlo automáticamente. El siguiente ejemplo accede al sitio de prueba de cloudflare-turnstile. Después de ingresar el nombre de usuario y la contraseña, utiliza el método waitForFunction para esperar los datos de window.turnstile.getResponse(), asegurando que el desafío se haya superado correctamente. Luego, toma una captura de pantalla y hace clic en el botón de inicio de sesión para navegar a la siguiente página.
Pasos y ejemplo de código:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Esperar a que turnstile se desbloquee correctamente
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });Después de ejecutar este script, verá el efecto de desbloqueo a través de capturas de pantalla.
Usar Scrapeless Web Unlocker para el renderizado de JavaScript
Para sitios web protegidos por Cloudflare donde el contenido principal se basa en la ejecución de JavaScript del lado del cliente para la carga y visualización completas, Scrapeless Web Unlocker proporciona una solución dedicada.
Scrapeless Universal API permite el renderizado de JavaScript y la interacción dinámica, convirtiéndolo en una herramienta eficaz para eludir Cloudflare.
Renderizado de JavaScript
El renderizado de JavaScript admite el manejo de contenido cargado dinámicamente y aplicaciones de una sola página (SPA). Admite un entorno de navegador completo, manejando interacciones de página más complejas y requisitos de renderizado.
Con js_render=true, usaremos el navegador para la solicitud
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"js_render": true
},
"proxy": {
"country": "US"
}
}Instrucciones de JavaScript
Proporciona un amplio conjunto de instrucciones de JavaScript, permitiendo la interacción dinámica con las páginas web.
Estas instrucciones permiten hacer clic en elementos, rellenar formularios, enviar formularios o esperar a que aparezcan elementos específicos, proporcionando flexibilidad para tareas como hacer clic en un botón “Leer más” o enviar un formulario.
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"js_render": true,
"instructions": [
{
"waitFor": [
".dynamic-content",
30000
]
// Esperar elemento
},
{
"click": [
"#load-more",
1000
]
// Hacer clic en el elemento
},
{
"fill": [
"#search-input",
"search term"
]
// Rellenar formulario
},
{
"keyboard": [
"press",
"Enter"
]
// Simular pulsación de tecla
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// Ejecutar JS personalizado
}
]
}
}Ejemplo de elusión de desafío
El siguiente ejemplo usa axios para enviar una solicitud al servicio Web Unlocker de Scrapeless. Habilita js_render y usa la instrucción waitFor en el parámetro instructions para esperar un elemento en la página después de eludir el desafío de Cloudflare:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
js_render: true,
instructions: [
{
waitFor: [
"main.page-content .challenge-info",
30000
]
}
]
},
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();Después de ejecutar el script anterior, podrá ver el HTML de la página que superó correctamente el desafío de Cloudflare en la consola.