वेब स्क्रैपिंग में Cloudflare बाईपास
स्क्रैपिंग ब्राउज़र और Cloudflare
यह तकनीकी दस्तावेज़ बताता है कि Cloudflare द्वारा स्थापित विभिन्न सुरक्षा चुनौतियों को संभालने के लिए Scrapeless स्क्रैपिंग ब्राउज़र और Scrapeless वेब अनलॉकर टूल का उपयोग कैसे करें। प्रमुख विशेषताओं में Cloudflare JS चुनौती, Cloudflare टर्नस्टाइल को बाईपास करना और Cloudflare द्वारा संरक्षित सामग्री तक पहुँचने के लिए जावास्क्रिप्ट रेंडरिंग को निष्पादित करना शामिल है। यह दस्तावेज़ प्रासंगिक पृष्ठभूमि ज्ञान, सुविधा परिचय, परिचालन चरण और कोड उदाहरण स्पष्टीकरण प्रदान करेगा।
Cloudflare चुनौतियों और सुरक्षा परतों को समझना
Cloudflare, एक लोकप्रिय वेब सुरक्षा और प्रदर्शन सेवा, मुख्य रूप से वेबसाइटों को दुर्भावनापूर्ण या अप्रत्याशित ट्रैफ़िक से बचाती है, जैसे कि बॉट और स्कैनर। इसके लिए, Cloudflare विभिन्न पता लगाने और रक्षा तंत्र लागू करता है, जिसमें शामिल हैं लेकिन सीमित नहीं हैं:
1. JS चुनौती (जावास्क्रिप्ट चुनौती): आगंतुक के ब्राउज़र को यह सत्यापित करने के लिए विशिष्ट जावास्क्रिप्ट कोड निष्पादित करने की आवश्यकता होती है कि यह मानक कार्यक्षमता के साथ एक वैध ब्राउज़र वातावरण है।
2. टर्नस्टाइल CAPTCHA विकल्प: मानव उपयोगकर्ताओं और बॉट के बीच अंतर करने के लिए एक कम घुसपैठ करने वाला सत्यापन तंत्र।
3. ब्राउज़र फ़िंगरप्रिंटिंग: आगंतुकों की पहचान और ट्रैक करने के लिए ब्राउज़र और डिवाइस की तकनीकी विशेषताओं (जैसे, उपयोगकर्ता-एजेंट, स्क्रीन रिज़ॉल्यूशन, इंस्टॉल किए गए फ़ॉन्ट, प्लगइन्स) को एकत्रित और विश्लेषण करता है।
4. दर सीमा: किसी विशिष्ट समय के भीतर एक ही स्रोत (जैसे, आईपी पता) से अनुरोधों की संख्या की निगरानी और सीमा निर्धारित करती है ताकि ब्रूट-फोर्सिंग या संसाधन दुरुपयोग को रोका जा सके।
ये सुरक्षा परतें बुनियादी HTTP अनुरोध पुस्तकालयों, सरल स्क्रिप्ट या अनुचित तरीके से कॉन्फ़िगर किए गए हेडलेस ब्राउज़रों को Cloudflare-सुरक्षित वेबसाइटों तक पहुँचने से रोकती हैं, जिसके परिणामस्वरूप सत्यापन विफलताएँ और पहुँच अस्वीकृति होती है।
Cloudflare JS चुनौती और अन्य चुनौतियों के बीच अंतर
Cloudflare JS चुनौती की विशिष्टता इसकी सत्यापन विधि में है। इसे केवल उपयोगकर्ताओं को एक साधारण इंटरैक्टिव कार्य पूरा करने की आवश्यकता नहीं है (जैसे, छवि पहचान); यह मांग करता है कि क्लाइंट वातावरण (ब्राउज़र) Cloudflare से गतिशील रूप से उत्पन्न, अक्सर अस्पष्ट, जावास्क्रिप्ट कोड को सफलतापूर्वक पार्स और निष्पादित करे। यह कोड पर्यावरण जाँच, कम्प्यूटेशनल रूप से गहन कार्य, या क्लाइंट की जटिल व्यवहार क्षमताओं की नकल करते हुए, एक वास्तविक ब्राउज़र की नकल करते हुए, अन्य तर्क करता है।
JS चुनौती को सफलतापूर्वक पारित करने में एक वैध क्लीयरेंस टोकन (आमतौर पर cf_clearance कुकी के रूप में) उत्पन्न करना शामिल है। यह टोकन साबित करता है कि क्लाइंट जावास्क्रिप्ट निष्पादन क्षमता सत्यापन पास कर गया है। कई स्वचालन उपकरणों में एक पूर्ण जावास्क्रिप्ट निष्पादन इंजन और यथार्थवादी ब्राउज़र वातावरण सिमुलेशन का अभाव होता है, इस प्रकार ऐसी चुनौतियों में विफल हो जाते हैं।
Scrapeless स्क्रैपिंग ब्राउज़र का उपयोग करके Cloudflare JS चुनौती को बाईपास करना
Scrapeless स्क्रैपिंग ब्राउज़र को जटिल वेबसाइट सुरक्षा उपायों को संभालने के लिए डिज़ाइन किया गया है, जिसमें Cloudflare JS चुनौती भी शामिल है।
चरण और कोड उदाहरण
पर्यावरण सेटअप
एक प्रोजेक्ट फ़ोल्डर बनाएँ
प्रोजेक्ट के लिए एक नया फ़ोल्डर बनाएँ, उदाहरण के लिए: scrapeless-bypass।
अपने टर्मिनल में फ़ोल्डर पर जाएँ:
cd path/to/scrapeless-bypassNode.js प्रोजेक्ट इनिशियलाइज़ करें
package.json फ़ाइल बनाने के लिए निम्न कमांड चलाएँ:
npm init -yआवश्यक निर्भरताएँ स्थापित करें
Puppeteer-core स्थापित करें, जो ब्राउज़र उदाहरणों से दूरस्थ कनेक्शन की अनुमति देता है:
npm install puppeteer-coreयदि Puppeteer पहले से ही आपके सिस्टम पर स्थापित नहीं है, तो पूर्ण संस्करण स्थापित करें:
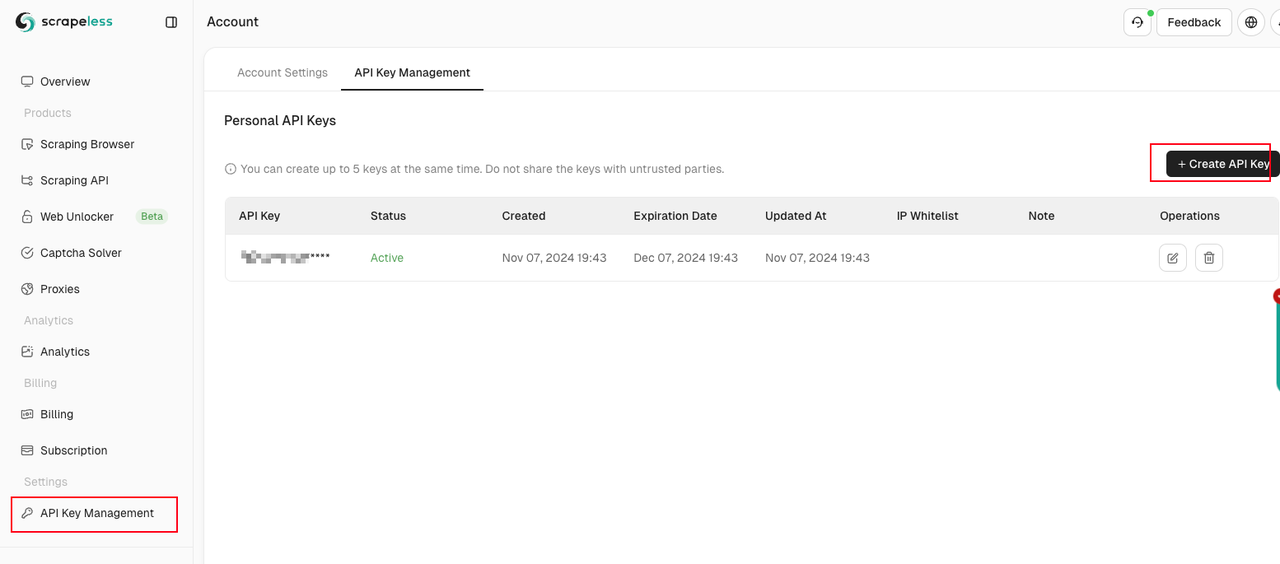
npm install puppeteer puppeteer-coreअपनी Scrapeless API कुंजी प्राप्त करें और कॉन्फ़िगर करें।
कनेक्ट करें और सुनिश्चित करें कि CAPTCHA सफलतापूर्वक हल हो गया है
लक्ष्य वेबसाइट तक पहुँचने के लिए ब्राउज़र से कनेक्ट करते समय Scrapeless स्वचालित रूप से CAPTCHA का पता लगाता है और हल करता है। हालाँकि, हमें यह सुनिश्चित करने की आवश्यकता है कि CAPTCHA सफलतापूर्वक हल हो गया है। Scrapeless स्क्रैपिंग ब्राउज़र कस्टम क्षमताओं के एक शक्तिशाली सेट के साथ मानक CDP (क्रोम डेवलपमेंट टूल्स प्रोटोकॉल) का विस्तार करता है। CDP API से लौटाए गए परिणामों की जाँच करके CAPTCHA सॉल्वर की स्थिति को सीधे देखा जा सकता है:
Captcha.detected: CAPTCHA का पता चलाCaptcha.solveFinished: CAPTCHA सफलतापूर्वक हल हो गयाCaptcha.solveFailed: CAPTCHA हल करने में विफल रहा
import puppeteer from "puppeteer-core";
import EventEmitter from 'events';
import { Scrapeless } from '@scrapeless-ai/sdk';
const emitter = new EventEmitter();
const client = new Scrapeless({ apiKey: 'API Key' });
const { browserWSEndpoint } = client.browser.create({
sessionName: 'sdk_test',
sessionTTL: 180,
proxyCountry: 'ANY',
sessionRecording: true,
fingerprint,
});
export async function example(url) {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null
});
console.log("Verbonden met Scrapeless browser");
try {
const page = await browser.newPage();
// Listen for captcha events
console.debug("addCaptchaListener: Start listening for captcha events");
await addCaptchaListener(page);
console.log("Navigated to URL:", url);
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 30000 });
console.log("onCaptchaFinished: Waiting for captcha solving to finish...");
await onCaptchaFinished()
// Screenshot for debugging
console.debug("Taking screenshot of the final page...");
await page.screenshot({ path: 'screenshot.png', fullPage: true });
} catch (error) {
console.error(error);
} finally {
await browser.close();
console.log("Browser closed");
}
}
async function addCaptchaListener(page) {
const client = await page.createCDPSession();
client.on("Captcha.detected", (msg) => {
console.debug("Captcha.detected: ", msg);
});
client.on("Captcha.solveFinished", async (msg) => {
console.debug("Captcha.solveFinished: ", msg);
emitter.emit("Captcha.solveFinished", msg);
client.removeAllListeners()
});
}
async function onCaptchaFinished(timeout = 60_000) {
return Promise.race([
new Promise((resolve) => {
emitter.on("Captcha.solveFinished", (msg) => {
resolve(msg);
});
}),
new Promise((_, reject) => setTimeout(() => reject('Timeout'), timeout))
])
}यह उदाहरण वर्कफ़्लो लक्ष्य वेबसाइट तक पहुँचता है और यह पुष्टि करता है कि Captcha.solveFinished CDP इवेंट सुनकर CAPTCHA सफलतापूर्वक हल हो गया है। अंत में, यह सत्यापन के लिए पृष्ठ का स्क्रीनशॉट कैप्चर करता है।
यह उदाहरण दो मुख्य विधियाँ परिभाषित करता है:
addCaptchaListener: ब्राउज़र सत्र के भीतर CAPTCHA ईवेंट सुनने के लिएonCaptchaFinished: CAPTCHA हल होने तक प्रतीक्षा करने के लिए
ऊपर दिए गए उदाहरण कोड का उपयोग इस लेख में चर्चा किए गए तीन सामान्य CAPTCHA प्रकारों के लिए CDP ईवेंट सुनने के लिए किया जा सकता है: reCAPTCHA v2, Cloudflare Turnstile, और Cloudflare 5s चुनौती।
ध्यान दें कि Cloudflare 5s चुनौती कुछ हद तक विशेष है। कभी-कभी यह वास्तविक चुनौती को ट्रिगर नहीं करता है, और सफलता के लिए केवल CDP ईवेंट पहचान पर भरोसा करने से समय सीमा समाप्त हो सकती है। इसलिए, चुनौती के बाद पृष्ठ पर दिखाई देने वाले किसी विशिष्ट तत्व की प्रतीक्षा करना एक अधिक स्थिर समाधान है।
Scrapeless ब्राउज़रलेस वेबसोकेट से कनेक्ट करना
Scrapeless एक वेबसोकेट कनेक्शन प्रदान करता है, जिससे Puppeteer को Cloudflare चुनौतियों को बाईपास करते हुए, सीधे हेडलेस ब्राउज़र के साथ बातचीत करने की अनुमति मिलती है।
पूर्ण वेबसोकेट कनेक्शन पता:
wss://browser.scrapeless.com/api/v2/browser?token=APIKey&sessionTTL=180&proxyCountry=ANYकोड उदाहरण: Cloudflare चुनौती को बाईपास करना
Scrapeless की ब्राउज़रलेस सेवा से जुड़ने के लिए हमें केवल निम्न कोड की आवश्यकता है।
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com/api/v2';
const query = new URLSearchParams({
token: API_KEY,
sessionTTL: '180', // The life cycle of a browser session, in seconds
proxyCountry: 'GB', // Agent country
proxySessionId: 'test_session_id', // The proxy session id is used to keep the proxy ip unchanged. The session time is 3 minutes by default, based on the proxySessionDuration setting.
proxySessionDuration: '5' // Agent session time, unit minutes
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')Cloudflare-सुरक्षित वेबसाइटों तक पहुँचना और स्क्रीनशॉट सत्यापन
अगला, हम scrapeless browserless का उपयोग सीधे cloudflare-चुनौती परीक्षण साइट तक पहुँचने और एक स्क्रीनशॉट जोड़ने के लिए करते हैं, जिससे दृश्य सत्यापन की अनुमति मिलती है। स्क्रीनशॉट लेने से पहले, ध्यान दें कि आपको पृष्ठ पर तत्वों की प्रतीक्षा करने के लिए waitForSelector का उपयोग करने की आवश्यकता है, यह सुनिश्चित करते हुए कि Cloudflare चुनौती सफलतापूर्वक बाईपास हो गई है।
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// By waiting for elements in the site page, ensuring that the Cloudflare challenge has been successfully bypassed.
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
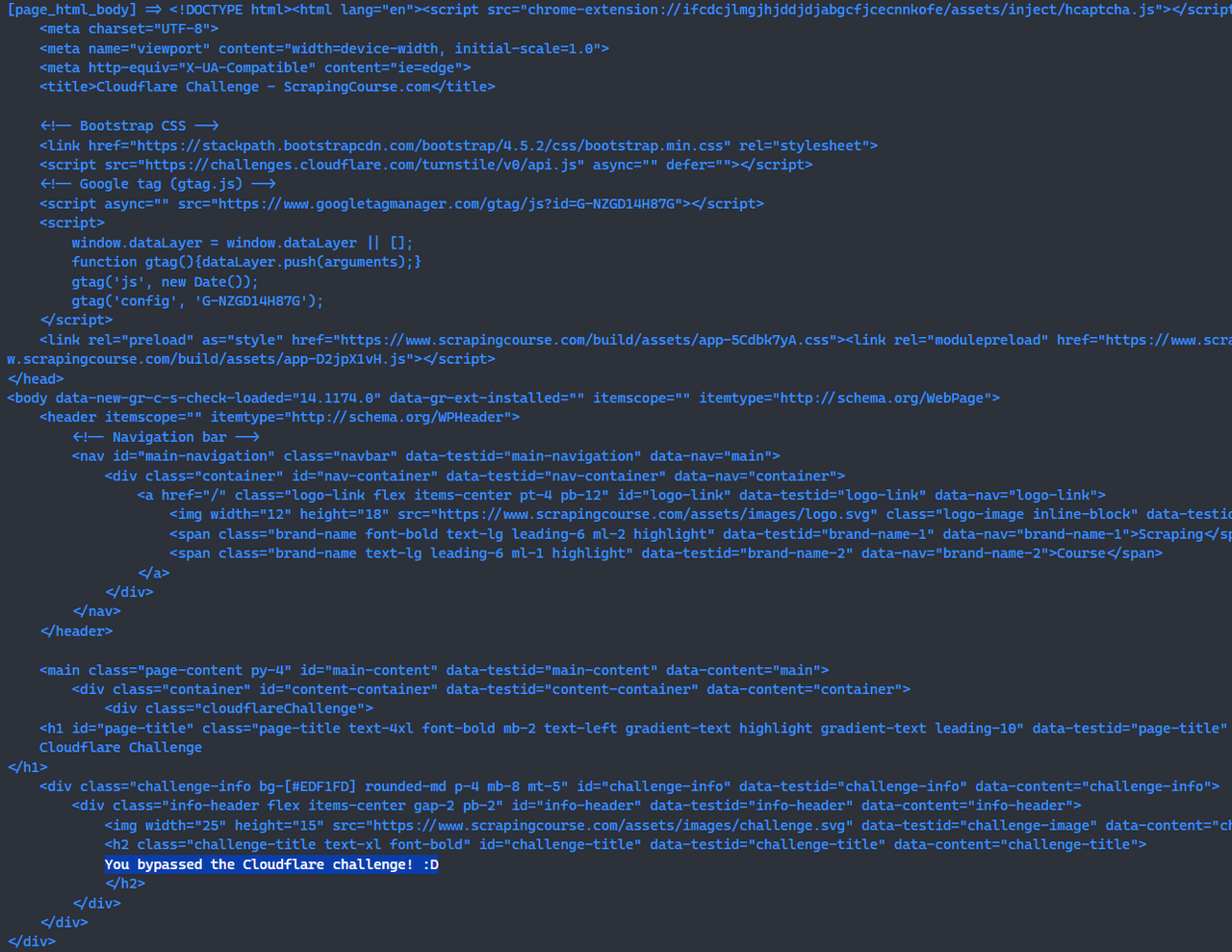
await page.screenshot({path: 'challenge-bypass.png'});इस बिंदु पर, आपने Scrapeless Browserless का उपयोग करके Cloudflare चुनौती को बाईपास कर दिया है।

cf_clearance कुकी और शीर्षलेख प्राप्त करना
Cloudflare चुनौती पास करने के बाद, आप सफल पृष्ठ से अनुरोध शीर्षलेख और cf_clearance कुकी प्राप्त कर सकते हैं।
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueअनुरोध शीर्षलेखों को कैप्चर करने और Cloudflare चुनौती के बाद पृष्ठ अनुरोधों का मिलान करने के लिए अनुरोध अवरोधन सक्षम करें।
await page.setRequestInterception(true);
page.on('request', request => {
// Match page requests after cloudflare challenge
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});Scrapeless स्क्रैपिंग ब्राउज़र का उपयोग करके Cloudflare टर्नस्टाइल को बाईपास करना
Scrapeless स्क्रैपिंग ब्राउज़र Cloudflare टर्नस्टाइल चुनौतियों को भी संभालता है।
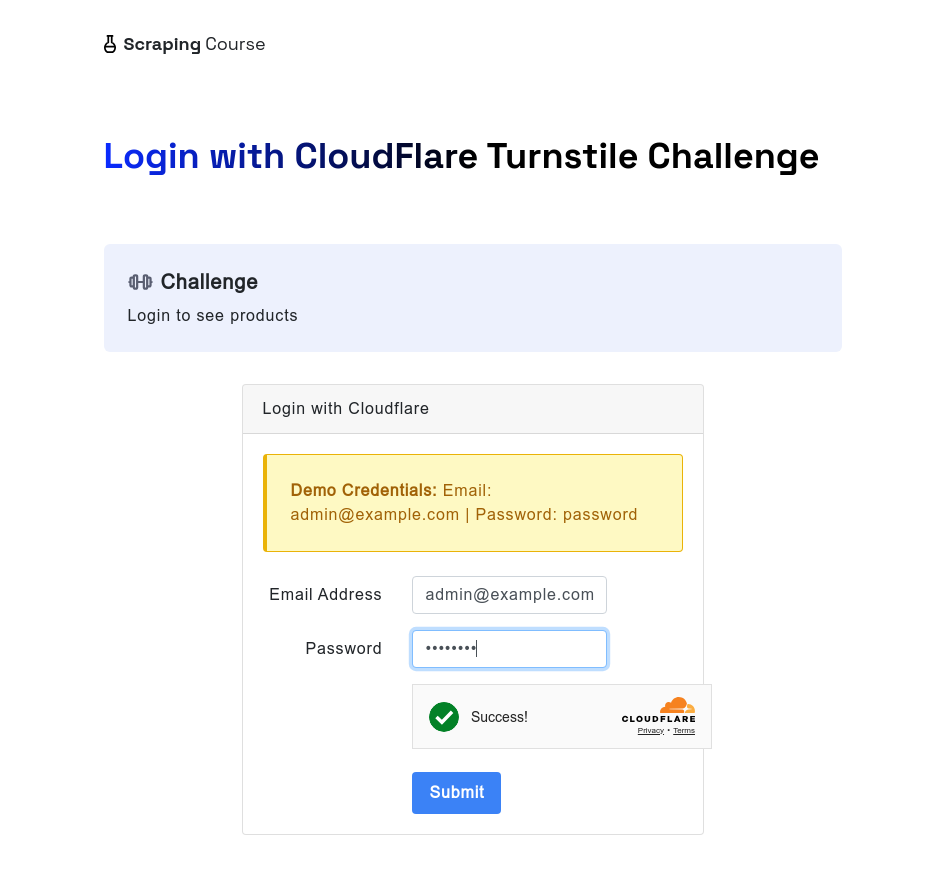
इसी प्रकार, जब Cloudflare टर्नस्टाइल का सामना करना पड़ता है, तो ब्राउज़रलेस स्क्रैपिंग ब्राउज़र अभी भी इसे स्वचालित रूप से संभाल सकता है। निम्न उदाहरण cloudflare-turnstile परीक्षण साइट तक पहुँचता है। उपयोगकर्ता नाम और पासवर्ड दर्ज करने के बाद, यह window.turnstile.getResponse() से डेटा की प्रतीक्षा करने के लिए waitForFunction विधि का उपयोग करता है, यह सुनिश्चित करता है कि चुनौती सफलतापूर्वक बाईपास हो गई है। फिर, यह एक स्क्रीनशॉट लेता है और अगले पृष्ठ पर नेविगेट करने के लिए लॉगिन बटन पर क्लिक करता है।
चरण और कोड उदाहरण:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Wait for turnstile to unlock successfully
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });यह स्क्रिप्ट चलाने के बाद, आप स्क्रीनशॉट के माध्यम से अनलॉकिंग प्रभाव देखेंगे।
जावास्क्रिप्ट रेंडरिंग के लिए Scrapeless वेब अनलॉकर का उपयोग करना
Cloudflare द्वारा संरक्षित वेबसाइटों के लिए जहाँ मुख्य सामग्री पूर्ण लोडिंग और प्रदर्शन के लिए क्लाइंट-साइड जावास्क्रिप्ट निष्पादन पर निर्भर करती है, Scrapeless वेब अनलॉकर एक समर्पित समाधान प्रदान करता है।
Scrapeless यूनिवर्सल API जावास्क्रिप्ट रेंडरिंग और गतिशील इंटरैक्शन को सक्षम बनाता है, जिससे यह Cloudflare को बाईपास करने के लिए एक प्रभावी उपकरण बन जाता है।
जावास्क्रिप्ट रेंडरिंग
जावास्क्रिप्ट रेंडरिंग गतिशील रूप से लोड की गई सामग्री और SPA (सिंगल-पेज एप्लिकेशन) को संभालने का समर्थन करता है। यह अधिक जटिल पृष्ठ इंटरैक्शन और रेंडरिंग आवश्यकताओं को संभालते हुए, एक पूर्ण ब्राउज़र वातावरण का समर्थन करता है।
input.jsRender.enabled=true के साथ, हम अनुरोध के लिए ब्राउज़र का उपयोग करेंगे
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"jsRender": {
"enabled": true
}
},
"proxy": {
"country": "US"
}
}जावास्क्रिप्ट निर्देश
जावास्क्रिप्ट निर्देशों का एक व्यापक सेट प्रदान करता है, जिससे वेब पेजों के साथ गतिशील बातचीत की अनुमति मिलती है।
ये निर्देश तत्वों पर क्लिक करने, फ़ॉर्म भरने, फ़ॉर्म सबमिट करने या विशिष्ट तत्वों के प्रकट होने की प्रतीक्षा करने में सक्षम बनाते हैं, “अधिक पढ़ें” बटन पर क्लिक करने या फ़ॉर्म सबमिट करने जैसे कार्यों के लिए लचीलापन प्रदान करते हैं।
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"jsRender": {
"enabled": true,
"instructions": [
{
"waitFor": [
".dynamic-content",
30000
]
// Wait for element
},
{
"click": [
"#load-more",
1000
]
// Click element
},
{
"fill": [
"#search-input",
"search term"
]
// Fill form
},
{
"keyboard": [
"press",
"Enter"
]
// Simulate key press
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// Execute custom JS
}
]
}
}
}चुनौती बाईपास उदाहरण
निम्नलिखित उदाहरण Scrapeless की वेब अनलॉकर सेवा के लिए अनुरोध भेजने के लिए axios का उपयोग करता है। यह input.jsRender.enabled को सक्षम करता है और Cloudflare चुनौती को बाईपास करने के बाद पृष्ठ पर किसी तत्व की प्रतीक्षा करने के लिए input.jsRender.instructions पैरामीटर में waitFor निर्देश का उपयोग करता है:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v2/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
jsRender: {
enabled: true,
instructions: [
{
waitFor: [
"main.page-content .challenge-info",
30000
]
}
]
}
}
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();उपरोक्त स्क्रिप्ट चलाने के बाद, आप कंसोल में उस पृष्ठ का HTML देख पाएंगे जिसने Cloudflare चुनौती को सफलतापूर्वक बाईपास कर दिया है।