Browser MCP
Scrapeless Browser MCP Server ChatGPT, Claude जैसे मॉडल और Cursor तथा Windsurf जैसे उपकरणों को बाहरी क्षमताओं की एक विस्तृत श्रृंखला से सहज रूप से जोड़ता है, जिसमें शामिल हैं:
- पृष्ठ-स्तर पर नेविगेशन और इंटरैक्शन के लिए ब्राउज़र ऑटोमेशन
- डायनामिक, जेएस-भारी साइटों को स्क्रैप करें—एचटीएमएल, मार्कडाउन या स्क्रीनशॉट के रूप में निर्यात करें
| एमसीपी प्रकार | तकनीकी स्टैक | फायदे | प्राथमिक इकोसिस्टम | इसके लिए सबसे अच्छा है |
|---|---|---|---|---|
| Chrome DevTools MCP | Node.js / Puppeteer | आधिकारिक मानक, मजबूत, गहन प्रदर्शन विश्लेषण उपकरण। | ब्रॉड (Gemini, Copilot, Cursor) | CI/CD ऑटोमेशन, क्रॉस-IDE वर्कफ़्लो और गहन प्रदर्शन ऑडिट। |
| Playwright MCP | Node.js / Playwright | पिक्सेल के बजाय एक्सेसिबिलिटी ट्री का उपयोग करता है; विजन के बिना नियतात्मक और एलएलएम-अनुकूल। | ब्रॉड (VS Code, Copilot) | विश्वसनीय, संरचित ऑटोमेशन जो मामूली UI परिवर्तनों से टूटने की कम संभावना रखता है। |
| Scrapeless Browser MCP | क्लाउड सेवा | शून्य स्थानीय सेटअप, स्केलेबल क्लाउड ब्राउज़र, जटिल साइटों और एंटी-बॉट उपायों को संभालता है। | एपीआई-संचालित (कोई भी क्लाइंट) | बड़े पैमाने पर, समानांतर ऑटोमेशन कार्य और मजबूत बॉट डिटेक्शन वाली वेबसाइटों के साथ इंटरैक्ट करना। |
समर्थित एमसीपी उपकरण
| नाम | विवरण |
|---|---|
| browser_create | Scrapeless का उपयोग करके क्लाउड ब्राउज़र सत्र बनाएं या पुनः उपयोग करें। |
| browser_close | क्लाउड ब्राउज़र को डिस्कनेक्ट करके वर्तमान सत्र को बंद करता है। |
| browser_goto | ब्राउज़र को निर्दिष्ट URL पर नेविगेट करें। |
| browser_go_back | ब्राउज़र इतिहास में एक कदम पीछे जाएं। |
| browser_go_forward | ब्राउज़र इतिहास में एक कदम आगे जाएं। |
| browser_click | पृष्ठ पर एक विशिष्ट तत्व पर क्लिक करें। |
| browser_type | निर्दिष्ट इनपुट फ़ील्ड में टेक्स्ट टाइप करें। |
| browser_press_key | एक कुंजी दबाने का अनुकरण करें। |
| browser_wait_for | एक विशिष्ट पृष्ठ तत्व के दिखाई देने की प्रतीक्षा करें। |
| browser_wait | एक निश्चित अवधि के लिए निष्पादन रोकें। |
| browser_screenshot | वर्तमान पृष्ठ का स्क्रीनशॉट कैप्चर करें। |
| browser_get_html | वर्तमान पृष्ठ का पूरा HTML प्राप्त करें। |
| browser_get_text | वर्तमान पृष्ठ से सभी दृश्यमान टेक्स्ट प्राप्त करें। |
| browser_scroll | पृष्ठ के अंत तक स्क्रॉल करें। |
| browser_scroll_to | एक विशिष्ट तत्व को दृश्य में स्क्रॉल करें। |
| scrape_html | एक URL को स्क्रैप करें और उसकी पूरी HTML सामग्री लौटाएं। |
| scrape_markdown | एक URL को स्क्रैप करें और उसकी सामग्री को मार्कडाउन के रूप में लौटाएं। |
| scrape_screenshot | किसी भी वेबपेज का उच्च-गुणवत्ता वाला स्क्रीनशॉट कैप्चर करें। |
शुरू करना
अपनी Scrapeless API कुंजी प्राप्त करें
Scrapeless में लॉग इन करें और अपना API टोकन प्राप्त करें।

अपने एमसीपी क्लाइंट को कॉन्फ़िगर करें
Scrapeless MCP सर्वर Stdio और Streamable HTTP दोनों ट्रांसपोर्ट मोड का समर्थन करता है।
🖥️ Stdio (स्थानीय निष्पादन)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}🌐 स्ट्रीमेबल HTTP (होस्टेड एपीआई मोड)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}उन्नत विकल्प
वैकल्पिक मापदंडों के साथ ब्राउज़र सत्र व्यवहार को अनुकूलित करें। इन्हें पर्यावरण चर (Stdio के लिए) या HTTP हेडर (स्ट्रीमेबल HTTP के लिए) के माध्यम से सेट किया जा सकता है:
| Stdio (पर्यावरण चर) | स्ट्रीमेबल HTTP (HTTP हेडर) | विवरण |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | सत्र की निरंतरता के लिए एक पुन: प्रयोज्य ब्राउज़र प्रोफ़ाइल आईडी निर्दिष्ट करता है। |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | कुकीज़, स्थानीय स्टोरेज आदि के लिए स्थायी स्टोरेज सक्षम करता है। |
| BROWSER_SESSION_TTL | x-browser-session-ttl | सेकंड में अधिकतम सत्र टाइमआउट को परिभाषित करता है। निष्क्रियता की इस अवधि के बाद सत्र स्वचालित रूप से समाप्त हो जाएगा। |
उपयोग के मामले
वेब स्क्रैपिंग और डेटा संग्रह
- ई-कॉमर्स मॉनिटरिंग: कीमतों, स्टॉक की स्थिति और विवरणों को इकट्ठा करने के लिए स्वचालित रूप से उत्पाद पृष्ठों पर जाएं।
- बाजार अनुसंधान: विश्लेषण और तुलना के लिए समाचार, समीक्षाएं या कंपनी पृष्ठों को बैच में स्क्रैप करें।
- सामग्री एकत्रीकरण: केंद्रीकृत संग्रह के लिए पृष्ठ सामग्री, पोस्ट और टिप्पणियां निकालें।
- लीड जनरेशन: कॉर्पोरेट वेबसाइटों या निर्देशिकाओं से संपर्क जानकारी और कंपनी विवरण इकट्ठा करें।
परीक्षण और गुणवत्ता आश्वासन
- कार्य सत्यापन: पृष्ठों के अपेक्षित व्यवहार को सुनिश्चित करने के लिए क्लिक, टाइपिंग और तत्व प्रतीक्षा का उपयोग करें।
- उपयोगकर्ता यात्रा परीक्षण: वर्कफ़्लो को मान्य करने के लिए वास्तविक उपयोगकर्ता इंटरैक्शन (टाइपिंग, क्लिकिंग, स्क्रॉलिंग) का अनुकरण करें।
- रिग्रेशन परीक्षण सहायता: UI या सामग्री परिवर्तनों का पता लगाने के लिए प्रमुख पृष्ठों के स्क्रीनशॉट कैप्चर करें और तुलना करें।
कार्य और वर्कफ़्लो ऑटोमेशन
- फॉर्म भरना: वेब फ़ॉर्म (जैसे पंजीकरण, सर्वेक्षण) को स्वचालित रूप से पूरा और सबमिट करें।
- डेटा कैप्चर और रिपोर्ट जनरेशन: विश्लेषण के लिए समय-समय पर पृष्ठ डेटा निकालें और HTML या स्क्रीनशॉट के रूप में सहेजें।
- सरल प्रशासनिक कार्य: सिमुलेटेड क्लिक और टाइपिंग का उपयोग करके दोहराए जाने वाले बैकएंड या वेब-आधारित संचालन को स्वचालित करें।
शोकेस
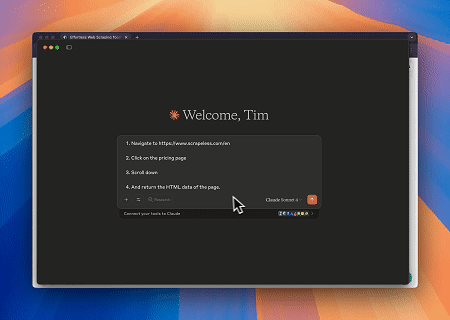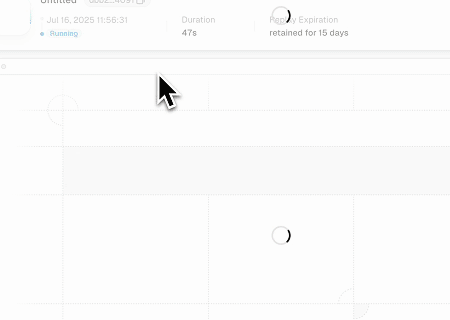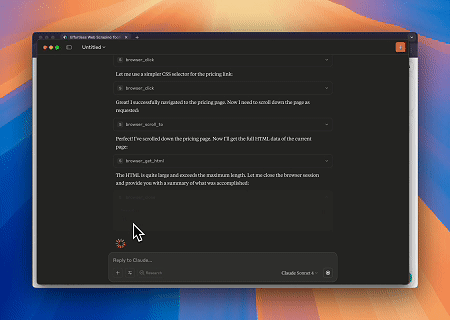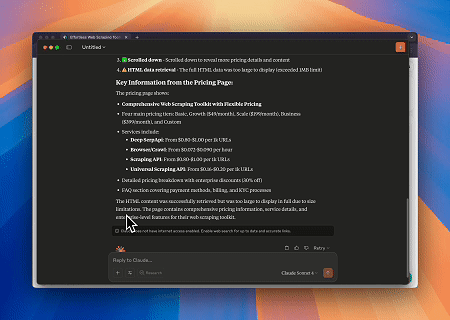
केस 1: क्लाउड के साथ वेब इंटरैक्शन और डेटा एक्सट्रैक्शन ऑटोमेशन
ब्राउज़र एमसीपी सर्वर का उपयोग करके, क्लाउड संवादात्मक कमांड के माध्यम से जटिल वेब संचालन — जैसे नेविगेशन, क्लिकिंग, स्क्रॉलिंग और डेटा स्क्रैपिंग — कर सकता है, जिसमें लाइव सत्रों के माध्यम से वास्तविक समय निष्पादन पूर्वावलोकन भी शामिल है।
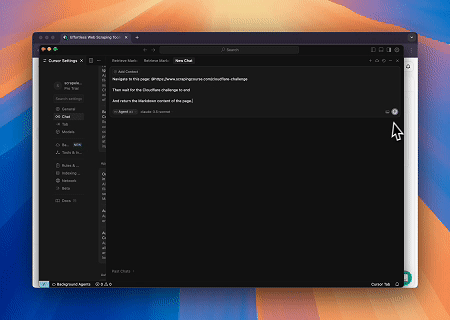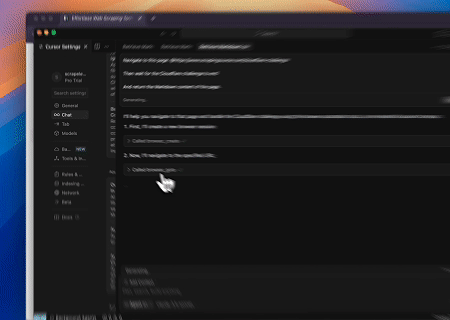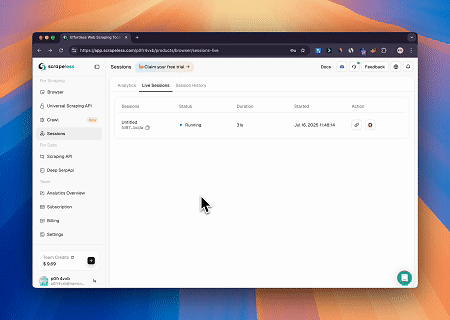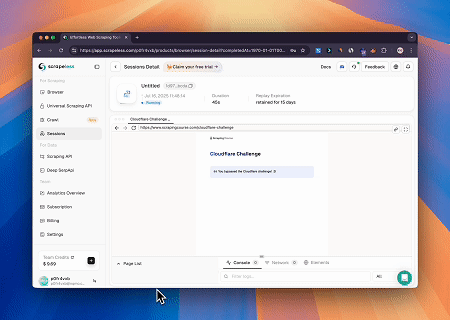
केस 2: लक्ष्य पृष्ठ सामग्री को पुनः प्राप्त करने के लिए क्लाउडफ्लेयर को बायपास करना
ब्राउज़र एमसीपी सर्वर का उपयोग करके, क्लाउडफ्लेयर-संरक्षित पृष्ठों तक स्वचालित रूप से पहुँचा जाता है, और पूरा होने पर, पृष्ठ सामग्री को निकाला जाता है और मार्कडाउन प्रारूप में लौटाया जाता है।
एक क्लाउड ब्राउज़र, अनंत एकीकरण
क्रोम देवटूल्स एमसीपी, प्लेराइट एमसीपी और स्क्रैपलेस ब्राउज़र एमसीपी — एक ही नींव साझा करते हैं: वे सभी Scrapeless Cloud Browser से जुड़ते हैं।
पारंपरिक स्थानीय ब्राउज़र ऑटोमेशन के विपरीत, Scrapeless ब्राउज़र पूरी तरह से क्लाउड में चलता है, जो डेवलपर्स और एआई एजेंटों के लिए बेजोड़ लचीलापन और स्केलेबिलिटी प्रदान करता है।
यहां बताया गया है कि यह वास्तव में इसे शक्तिशाली क्या बनाता है:
- निर्बाध एकीकरण: Puppeteer, Playwright और CDP के साथ पूरी तरह से संगत, कोड की एक पंक्ति के साथ मौजूदा परियोजनाओं से सहज माइग्रेशन की अनुमति देता है।
- वैश्विक आईपी कवरेज: 195+ देशों में आवासीय, आईएसपी और असीमित आईपी पूल तक पहुंच, पारदर्शी और लागत प्रभावी दर ($0.6–1.8/जीबी) पर। बड़े पैमाने पर वेब डेटा ऑटोमेशन के लिए बिल्कुल सही।
- पृथक प्रोफ़ाइल: प्रत्येक कार्य एक समर्पित, स्थायी वातावरण में चलता है, जो सत्र अलगाव, बहु-खाता प्रबंधन और दीर्घकालिक स्थिरता सुनिश्चित करता है।
- असीमित समवर्ती स्केलिंग: ऑटो-स्केलिंग इन्फ्रास्ट्रक्चर के साथ तुरंत 50-1000+ ब्राउज़र इंस्टेंस लॉन्च करें — कोई सर्वर सेटअप नहीं, कोई प्रदर्शन बाधा नहीं।
- दुनिया भर में एज नोड्स: अल्ट्रा-लो लेटेंसी और अन्य क्लाउड ब्राउज़रों की तुलना में 2-3 गुना तेज़ स्टार्टअप के लिए कई वैश्विक नोड्स पर तैनात करें।
- एंटी-डिटेक्शन: reCAPTCHA, Cloudflare Turnstile और AWS WAF के लिए अंतर्निर्मित समाधान, सख्त सुरक्षा परतों के तहत भी अबाधित ऑटोमेशन सुनिश्चित करते हैं।
- विज़ुअल डीबगिंग: लाइव व्यू के माध्यम से मानव-मशीन इंटरैक्टिव डीबगिंग और वास्तविक समय प्रॉक्सी ट्रैफिक मॉनिटरिंग प्राप्त करें। समस्याओं को शीघ्रता से पहचानने और संचालन को अनुकूलित करने के लिए सेशन रिकॉर्डिंग के माध्यम से सत्रों को पृष्ठ-दर-पृष्ठ रीप्ले करें।
एकीकरण
क्लाउड डेस्कटॉप
- क्लाउड डेस्कटॉप खोलें
- यहां जाएं:
सेटिंग्स→टूल्स→एमसीपी सर्वर - “एमसीपी सर्वर जोड़ें” पर क्लिक करें
- ऊपर दिए गए
Stdioयास्ट्रीमेबल HTTPकॉन्फ़िग में से किसी एक को पेस्ट करें - सर्वर को सहेजें और सक्षम करें
- क्लाउड अब वेब क्वेरी जारी करने, सामग्री निकालने और स्क्रैपलेस का उपयोग करके पृष्ठों के साथ इंटरैक्ट करने में सक्षम होगा
कर्सर आईडीई
- कर्सर खोलें
- Cmd + Shift + P दबाएं और खोजें:
एमसीपी सर्वर कॉन्फ़िगर करें - ऊपर दिए गए प्रारूप का उपयोग करके Scrapeless MCP कॉन्फ़िग जोड़ें
- फ़ाइल सहेजें और कर्सर को पुनरारंभ करें (यदि आवश्यक हो)
- अब आप कर्सर से इस तरह की बातें पूछ सकते हैं:
"इस त्रुटि के समाधान के लिए स्टैकओवरफ़्लो खोजें""इस पृष्ठ से HTML स्क्रैप करें"
- और यह पृष्ठभूमि में Scrapeless का उपयोग करेगा।