Crawl4AI
Crawl4AI एक ओपन-सोर्स वेब क्रॉलिंग और स्क्रैपिंग टूल है जिसे लार्ज लैंग्वेज मॉडल (LLMs), AI एजेंट्स और डेटा पाइपलाइन के साथ सहजता से इंटीग्रेट करने के लिए डिज़ाइन किया गया है। यह उच्च-गति, रीयल-टाइम डेटा एक्सट्रैक्शन को सक्षम बनाता है, जबकि लचीला और तैनात करने में आसान रहता है।
AI-संचालित वेब स्क्रैपिंग की मुख्य विशेषताओं में शामिल हैं:
- LLMs के लिए निर्मित: रिट्रीवल-ऑगमेंटेड जनरेशन (RAG) और फाइन-ट्यूनिंग के लिए अनुकूलित संरचित मार्कडाउन उत्पन्न करता है।
- लचीला ब्राउज़र नियंत्रण: सेशन प्रबंधन, प्रॉक्सी उपयोग और कस्टम हुक का समर्थन करता है।
- ह्यूरिस्टिक इंटेलिजेंस: डेटा पार्सिंग को अनुकूलित करने के लिए स्मार्ट एल्गोरिदम का उपयोग करता है।
- पूरी तरह से ओपन-सोर्स: किसी API कुंजी की आवश्यकता नहीं; डॉकर और क्लाउड प्लेटफॉर्म के माध्यम से परिनियोजित किया जा सकता है।
आधिकारिक दस्तावेज़ में अधिक जानें।
Crawl4AI के साथ स्क्रैपलेस का उपयोग क्यों करें?
Crawl4AI संरचित वेब डेटा एक्सट्रैक्शन में उत्कृष्ट है और LLM-संचालित पार्सिंग और पैटर्न-आधारित स्क्रैपिंग का समर्थन करता है। हालांकि, इसे अभी भी उन्नत एंटी-बॉट तंत्रों से निपटने में चुनौतियों का सामना करना पड़ सकता है, जैसे:
- क्लाउडफ्लेयर, AWS WAF, या reCAPTCHA द्वारा लोकल ब्राउज़र को ब्लॉक किया जाना
- बड़े पैमाने पर समवर्ती क्रॉलिंग के दौरान प्रदर्शन संबंधी बाधाएँ, जिसमें ब्राउज़र स्टार्टअप धीमा होता है
- जटिल डीबगिंग प्रक्रियाएँ जो समस्या निवारण को कठिन बनाती हैं
स्क्रैपलेस क्लाउड ब्राउज़र इन समस्याओं को पूरी तरह से हल करता है:
- वन-क्लिक एंटी-बॉट बाईपास: reCAPTCHA, क्लाउडफ्लेयर टर्नस्टाइल/चैलेंज, AWS WAF और अन्य को स्वचालित रूप से हैंडल करता है। Crawl4AI की संरचित एक्सट्रैक्शन शक्ति के साथ संयुक्त होने पर, यह सफलता दर को महत्वपूर्ण रूप से बढ़ाता है।
- असीमित समवर्ती स्केलिंग: सेकंडों में प्रति कार्य 50-1000+ ब्राउज़र इंस्टेंस लॉन्च करें, स्थानीय क्रॉलिंग प्रदर्शन सीमाओं को हटाते हुए और Crawl4AI दक्षता को अधिकतम करते हुए।
- 40%–80% लागत में कमी: समान क्लाउड सेवाओं की तुलना में, कुल लागत घटकर केवल 20%–60% हो जाती है। पे-एज-यू-गो मूल्य निर्धारण इसे छोटे पैमाने के प्रोजेक्ट्स के लिए भी किफायती बनाता है।
- विज़ुअल डीबगिंग उपकरण: Crawl4AI कार्यों को वास्तविक समय में देखने, विफलता के कारणों को तुरंत पहचानने और डीबगिंग ओवरहेड को कम करने के लिए सेशन रीप्ले और लाइव यूआरएल मॉनिटरिंग का उपयोग करें।
- शून्य-लागत एकीकरण: Playwright (Crawl4AI द्वारा उपयोग किया गया) के साथ मूल रूप से संगत, Crawl4AI को क्लाउड से कनेक्ट करने के लिए केवल एक पंक्ति कोड की आवश्यकता होती है — कोई कोड रिफैक्टरिंग आवश्यक नहीं।
- एज नोड सर्विस (ENS): कई वैश्विक नोड अन्य क्लाउड ब्राउज़र की तुलना में 2-3 गुना तेज स्टार्टअप गति और स्थिरता प्रदान करते हैं, Crawl4AI निष्पादन को गति प्रदान करते हैं।
- पृथक वातावरण और स्थायी सेशन: प्रत्येक स्क्रैपलेस प्रोफ़ाइल अपने स्वयं के वातावरण में स्थायी लॉगिन और पहचान अलगाव के साथ चलती है, सेशन हस्तक्षेप को रोकती है और बड़े पैमाने पर स्थिरता में सुधार करती है।
- लचीला फिंगरप्रिंट प्रबंधन: स्क्रैपलेस यादृच्छिक ब्राउज़र फिंगरप्रिंट उत्पन्न कर सकता है या कस्टम कॉन्फ़िगरेशन का उपयोग कर सकता है, जिससे डिटेक्शन जोखिमों को प्रभावी ढंग से कम किया जा सकता है और Crawl4AI की सफलता दर में सुधार होता है।
आरंभ करना
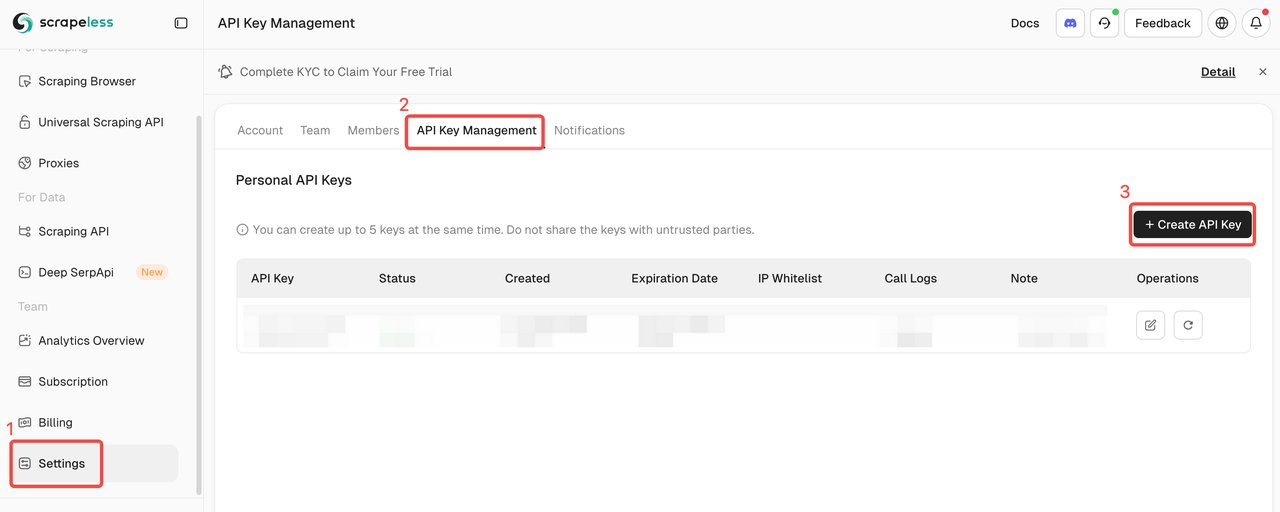
1. अपनी स्क्रैपलेस API कुंजी प्राप्त करें
स्क्रैपलेस में लॉग इन करें और अपनी API टोकन प्राप्त करें।
2. त्वरित शुरुआत
नीचे दिया गया उदाहरण दिखाता है कि Crawl4AI को स्क्रैपलेस क्लाउड ब्राउज़र से कितनी जल्दी और आसानी से कनेक्ट किया जा सकता है:
अधिक सुविधाओं और विस्तृत निर्देशों के लिए, परिचय देखें।
scrapeless_params = {
"token": "get your token from https://www.scrapeless.com",
"sessionName": "Scrapeless browser",
"sessionTTL": 1000,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url
)
)
कॉन्फ़िगरेशन के बाद, Crawl4AI CDP (क्रोम देवटूल्स प्रोटोकॉल) मोड के माध्यम से स्क्रैपलेस क्लाउड ब्राउज़र से कनेक्ट होता है, जो स्थानीय ब्राउज़र वातावरण के बिना वेब स्क्रैपिंग को सक्षम बनाता है। उपयोगकर्ता उच्च-समवर्ती और जटिल एंटी-बॉट परिदृश्यों की मांगों को पूरा करने के लिए प्रॉक्सी, फिंगरप्रिंट, सेशन पुन: उपयोग और अन्य सुविधाओं को आगे कॉन्फ़िगर कर सकते हैं।
3. वैश्विक स्वचालित प्रॉक्सी रोटेशन
स्क्रैपलेस 195 देशों में आवासीय IPs का समर्थन करता है। उपयोगकर्ता proxycountry का उपयोग करके लक्ष्य क्षेत्र को कॉन्फ़िगर कर सकते हैं, जिससे विशिष्ट स्थानों से अनुरोध भेजे जा सकते हैं। IPs स्वचालित रूप से घुमाए जाते हैं, जिससे ब्लॉकों से प्रभावी ढंग से बचा जा सकता है।
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Proxy Demo",
# Sets the target country/region for the proxy, sending requests via an IP address from that region. You can specify a country code (e.g., US for the United States, GB for the United Kingdom, ANY for any country). See country codes for all supported options."proxyCountry": "ANY",
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())
4. कस्टम ब्राउज़र फिंगरप्रिंट
वास्तविक उपयोगकर्ता व्यवहार का अनुकरण करने के लिए, स्क्रैपलेस यादृच्छिक रूप से उत्पन्न ब्राउज़र फिंगरप्रिंट का समर्थन करता है और कस्टम फिंगरप्रिंट पैरामीटर की भी अनुमति देता है। यह लक्षित वेबसाइटों द्वारा पता लगने के जोखिम को प्रभावी ढंग से कम करता है।
import json
import asyncio
from urllib.parse import quote, urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
# customize browser fingerprint
fingerprint = {
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36",
"platform": "Windows",
"screen": {
"width": 1280, "height": 1024
},
"localization": {
"languages": ["zh-HK", "en-US", "en"], "timezone": "Asia/Hong_Kong",
}
}
fingerprint_json = json.dumps(fingerprint)
encoded_fingerprint = quote(fingerprint_json)
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Fingerprint Demo",
"fingerprint": encoded_fingerprint,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())
5. प्रोफ़ाइल का पुन: उपयोग
स्क्रैपलेस प्रत्येक प्रोफ़ाइल को अपना स्वतंत्र ब्राउज़र वातावरण प्रदान करता है, जो स्थायी लॉगिन और पहचान अलगाव को सक्षम बनाता है। उपयोगकर्ता पिछली सेशन का पुन: उपयोग करने के लिए बस profileId प्रदान कर सकते हैं।
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Profile Demo",
"profileId": "your profileId",# create profile on scrapeless
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())