WebスクレイピングにおけるCloudflareバイパス
Scraping BrowserとCloudflare
この技術文書では、Scrapeless Scraping BrowserとScrapeless Web Unlockerツールを使用して、Cloudflareによって設定された様々なセキュリティ上の課題をどのように処理するかを説明します。主な機能には、Cloudflare JSチャレンジ、Cloudflare Turnstileのバイパス、およびCloudflareによって保護されているコンテンツにアクセスするためのJavaScriptレンダリングの実行が含まれます。このドキュメントでは、関連する背景知識、機能紹介、操作手順、コード例の説明を提供します。
Cloudflareのチャレンジとセキュリティレイヤーについて
Cloudflareは、人気の高いWebセキュリティとパフォーマンスサービスであり、主にボットやスキャナーなどの悪意のあるトラフィックや予期せぬトラフィックからWebサイトを保護します。この目的のために、Cloudflareは、以下を含むがこれらに限定されない、様々な検出および防御メカニズムを実装しています。
**1. JSチャレンジ(JavaScriptチャレンジ):**訪問者のブラウザが特定のJavaScriptコードを実行して、標準的な機能を備えた正当なブラウザ環境であることを確認する必要があります。
2. Turnstile CAPTCHA代替: 人間ユーザーとボットを区別するための、それほど邪魔にならない検証メカニズムです。
3. ブラウザフィンガープリンティング: ブラウザとデバイスの技術的な特性(例:User-Agent、画面解像度、インストールされているフォント、プラグイン)を収集および分析して、訪問者を識別および追跡します。
4. レート制限: 特定の期間内の単一ソース(例:IPアドレス)からのリクエスト数を監視および制限して、ブルートフォース攻撃やリソースの乱用を防ぎます。
これらのセキュリティレイヤーにより、基本的なHTTPリクエストライブラリ、単純なスクリプト、または正しく構成されていないヘッドレスブラウザは、Cloudflareで保護されたWebサイトにアクセスできなくなり、検証エラーとアクセス拒否が発生します。
Cloudflare JSチャレンジとその他のチャレンジの違い
Cloudflare JSチャレンジの独自性は、その検証方法にあります。単にユーザーに簡単なインタラクティブなタスク(例:画像認識)を完了させるのではなく、クライアント環境(ブラウザ)がCloudflareから動的に生成された、多くの場合難読化されたJavaScriptコードを正常に解析および実行することを要求します。このコードは、環境チェック、計算集約的なタスク、またはクライアントの複雑な動作能力を検証するためのその他のロジックを実行し、実際のブラウザを模倣します。
JSチャレンジに合格するには、有効なクリアランストークン(通常はcf_clearance Cookieの形をしています)を生成する必要があります。このトークンは、クライアントがJavaScript実行能力の検証に合格したことを証明します。多くの自動化ツールは、完全なJavaScript実行エンジンと現実的なブラウザ環境のシミュレーションを欠いているため、このようなチャレンジに失敗します。
Scrapeless Scraping Browserを使用したCloudflare JSチャレンジのバイパス
Scrapeless Scraping Browserは、Cloudflare JSチャレンジを含む、複雑なWebサイト保護対策を処理するように設計されています。
手順とコード例
環境設定
プロジェクトフォルダの作成
プロジェクト用の新しいフォルダを作成します(例:scrapeless-bypass)。
ターミナルでフォルダに移動します。
cd path/to/scrapeless-bypassNode.jsプロジェクトの初期化
次のコマンドを実行して、package.jsonファイルを作成します。
npm init -y必要な依存関係のインストール
ブラウザインスタンスへのリモート接続を許可するPuppeteer-coreをインストールします。
npm install puppeteer-coreシステムにPuppeteerがまだインストールされていない場合は、フルバージョンをインストールします。
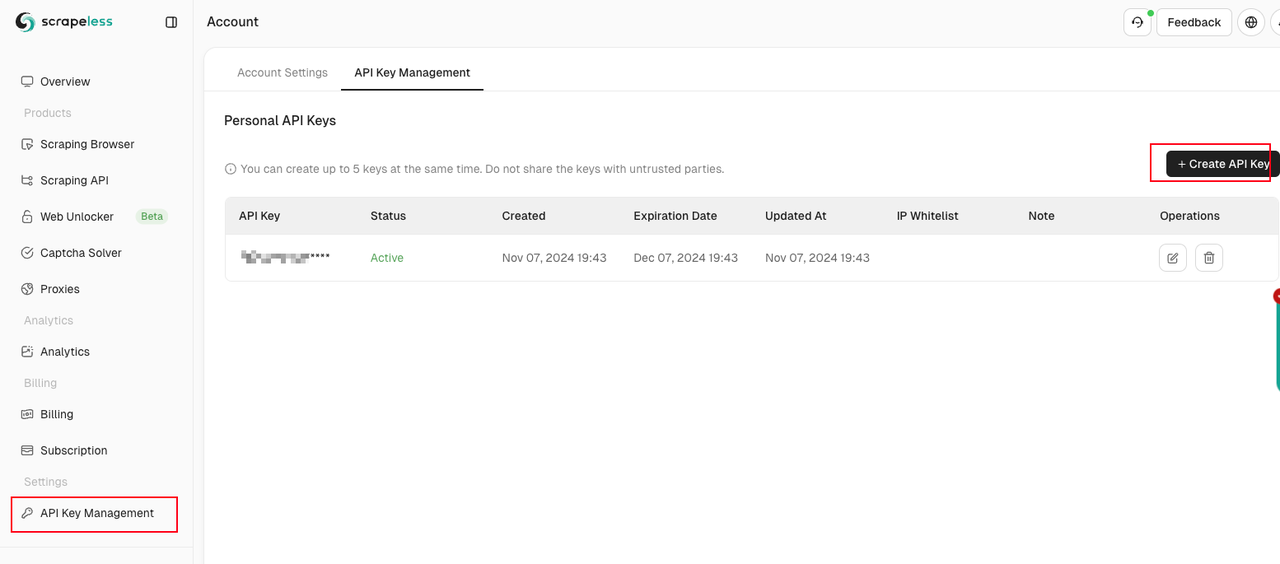
npm install puppeteer puppeteer-coreScrapeless APIキーの取得と設定
接続とCAPTCHAが正常に解決されたことの確認
Scrapelessは、ターゲットWebサイトにアクセスするためにブラウザに接続するときに、CAPTCHAを自動的に検出して解決します。ただし、CAPTCHAが正常に解決されたことを確認する必要があります。Scrapeless Scraping Browserは、標準のCDP(Chrome DevTools Protocol)を強力なカスタム機能で拡張しています。CAPTCHAソルバーのステータスは、CDP APIから返される結果をチェックすることで直接確認できます。
Captcha.detected: CAPTCHAが検出されましたCaptcha.solveFinished: CAPTCHAが正常に解決されましたCaptcha.solveFailed: CAPTCHAの解決に失敗しました
import puppeteer from "puppeteer-core";
import EventEmitter from 'events';
import { Scrapeless } from '@scrapeless-ai/sdk';
const emitter = new EventEmitter();
const client = new Scrapeless({ apiKey: 'API Key' });
const { browserWSEndpoint } = client.browser.create({
sessionName: 'sdk_test',
sessionTTL: 180,
proxyCountry: 'ANY',
sessionRecording: true,
fingerprint,
});
export async function example(url) {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null
});
console.log("Verbonden met Scrapeless browser");
try {
const page = await browser.newPage();
// Listen for captcha events
console.debug("addCaptchaListener: Start listening for captcha events");
await addCaptchaListener(page);
console.log("Navigated to URL:", url);
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 30000 });
console.log("onCaptchaFinished: Waiting for captcha solving to finish...");
await onCaptchaFinished()
// Screenshot for debugging
console.debug("Taking screenshot of the final page...");
await page.screenshot({ path: 'screenshot.png', fullPage: true });
} catch (error) {
console.error(error);
} finally {
await browser.close();
console.log("Browser closed");
}
}
async function addCaptchaListener(page) {
const client = await page.createCDPSession();
client.on("Captcha.detected", (msg) => {
console.debug("Captcha.detected: ", msg);
});
client.on("Captcha.solveFinished", async (msg) => {
console.debug("Captcha.solveFinished: ", msg);
emitter.emit("Captcha.solveFinished", msg);
client.removeAllListeners()
});
}
async function onCaptchaFinished(timeout = 60_000) {
return Promise.race([
new Promise((resolve) => {
emitter.on("Captcha.solveFinished", (msg) => {
resolve(msg);
});
}),
new Promise((_, reject) => setTimeout(() => reject('Timeout'), timeout))
])
}この例では、ターゲットWebサイトにアクセスし、Captcha.solveFinished CDPイベントをリッスンすることで、CAPTCHAが正常に解決されたことを確認します。最後に、検証のためにページのスクリーンショットをキャプチャします。
この例では、2つの主要なメソッドを定義しています。
addCaptchaListener: ブラウザセッション内でCAPTCHAイベントをリッスンするためonCaptchaFinished: CAPTCHAが解決されるまで待つため
上記のコード例は、この記事で説明されている3つの一般的なCAPTCHAタイプ(reCAPTCHA v2、Cloudflare Turnstile、Cloudflare 5秒チャレンジ)のCDPイベントをリッスンするために使用できます。
Cloudflare 5秒チャレンジはやや特殊です。実際にはチャレンジがトリガーされない場合もあり、成功のためにCDPイベント検出のみに依存すると、タイムアウトが発生する可能性があります。したがって、チャレンジ後にページに特定の要素が表示されるのを待つ方が、より安定したソリューションとなります。
Scrapeless Browserless WebSocketへの接続
ScrapelessはWebSocket接続を提供し、Puppeteerがヘッドレスブラウザと直接やり取りしてCloudflareチャレンジをバイパスできるようにします。
完全なWebSocket接続アドレス:
wss://browser.scrapeless.com/api/v2/browser?token=APIKey&sessionTTL=180&proxyCountry=ANYコード例:Cloudflareチャレンジのバイパス
Scrapelessのブラウザレスサービスに接続するには、次のコードのみが必要です。
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com/api/v2';
const query = new URLSearchParams({
token: API_KEY,
sessionTTL: '180', // The life cycle of a browser session, in seconds
proxyCountry: 'GB', // Agent country
proxySessionId: 'test_session_id', // The proxy session id is used to keep the proxy ip unchanged. The session time is 3 minutes by default, based on the proxySessionDuration setting.
proxySessionDuration: '5' // Agent session time, unit minutes
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')Cloudflareで保護されたWebサイトへのアクセスとスクリーンショットによる検証
次に、scrapeless browserlessを使用して、cloudflare-challengeテストサイトに直接アクセスし、スクリーンショットを追加して視覚的な検証を可能にします。スクリーンショットを撮る前に、waitForSelectorを使用してページ上の要素を待つ必要があることに注意してください。これにより、Cloudflareチャレンジが正常にバイパスされたことが保証されます。
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// By waiting for elements in the site page, ensuring that the Cloudflare challenge has been successfully bypassed.
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
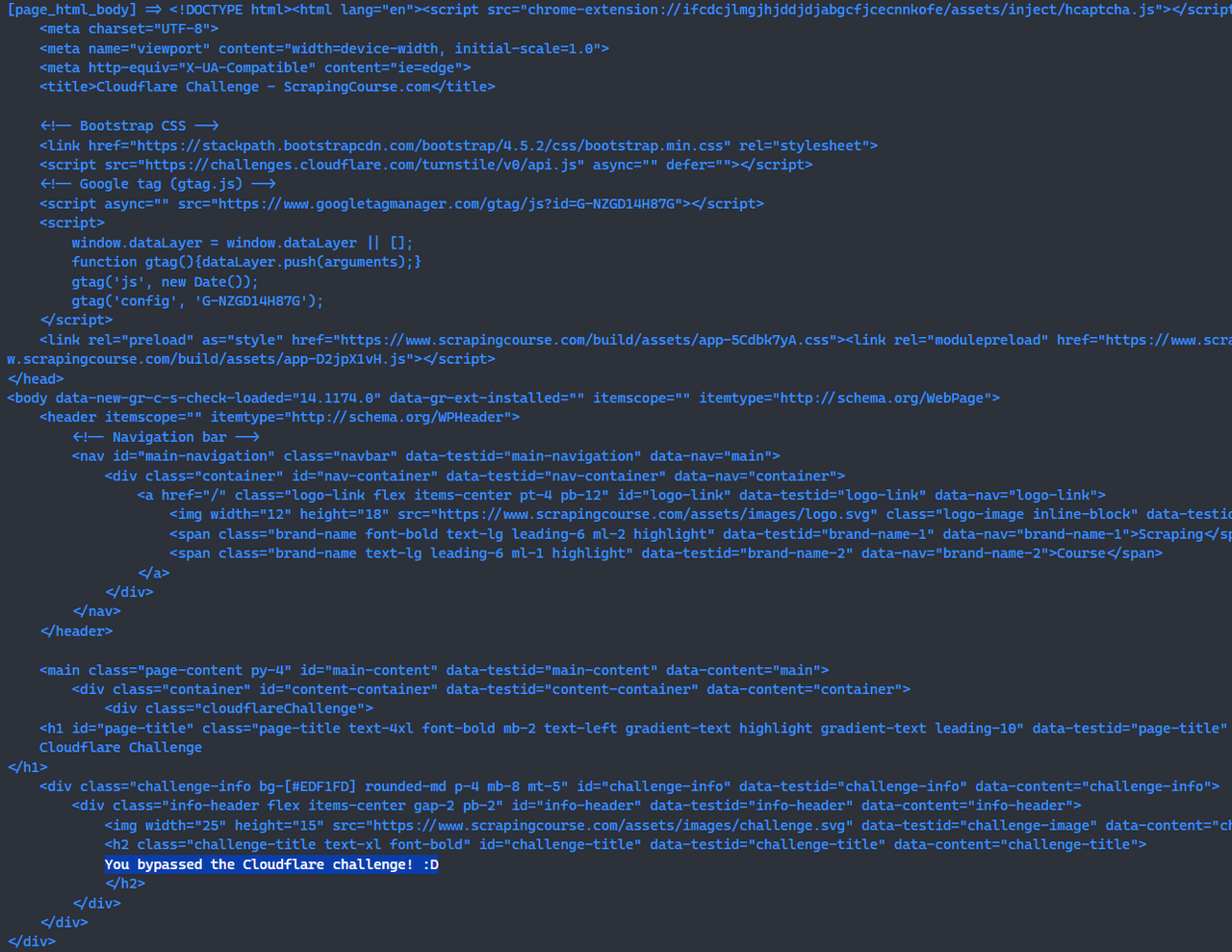
await page.screenshot({path: 'challenge-bypass.png'});この時点で、Scrapeless Browserlessを使用してCloudflareチャレンジをバイパスしました。

cf_clearance Cookieとヘッダーの取得
Cloudflareチャレンジに合格した後、成功したページからリクエストヘッダーとcf_clearance Cookieを取得できます。
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueリクエストインターセプトを有効にして、リクエストヘッダーをキャプチャし、Cloudflareチャレンジ後のページリクエストを一致させます。
await page.setRequestInterception(true);
page.on('request', request => {
// Match page requests after cloudflare challenge
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});Scrapeless Scraping Browserを使用したCloudflare Turnstileのバイパス
Scrapeless Scraping Browserは、Cloudflare Turnstileチャレンジも処理します。
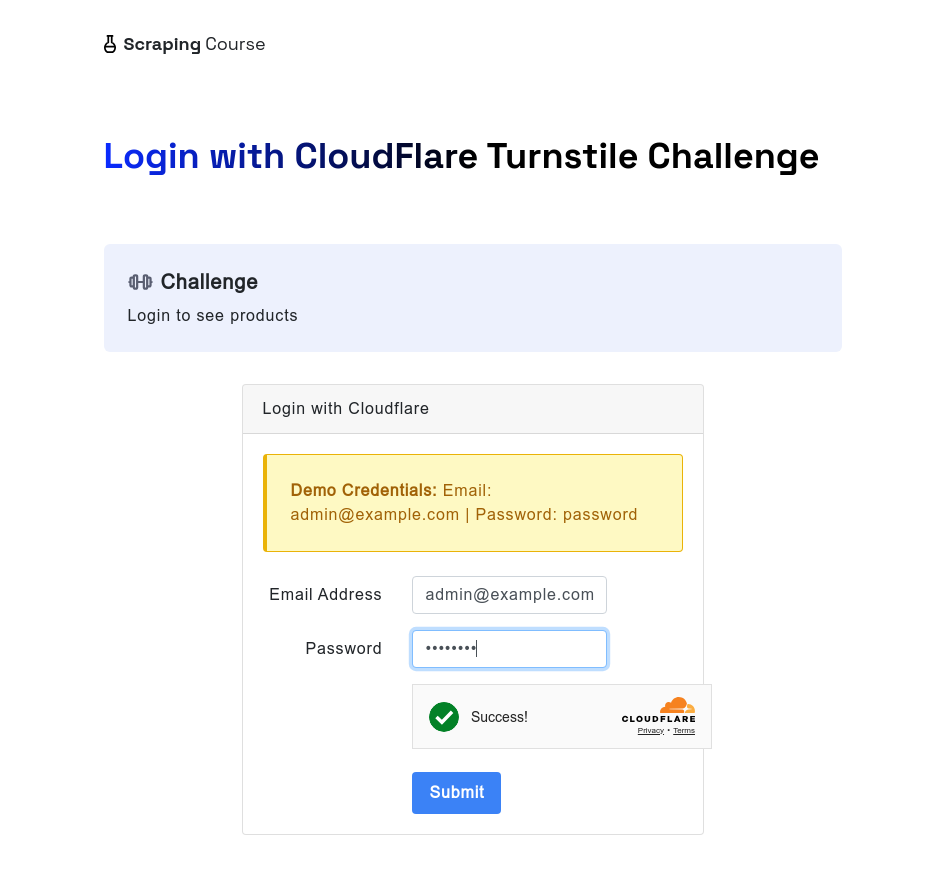
同様に、Cloudflare Turnstileに直面した場合でも、ブラウザレススクレイピングブラウザは自動的に処理できます。次の例では、cloudflare-turnstileテストサイトにアクセスします。ユーザー名とパスワードを入力した後、waitForFunctionメソッドを使用してwindow.turnstile.getResponse()からのデータが取得されるまで待機し、チャレンジが正常にバイパスされたことを確認します。次に、スクリーンショットを撮り、ログインボタンをクリックして次のページに移動します。
手順とコード例:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Wait for turnstile to unlock successfully
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });このスクリプトを実行した後、スクリーンショットでロック解除の効果を確認できます。
JavaScriptレンダリングのためのScrapeless Web Unlockerの使用
コアコンテンツがクライアント側のJavaScript実行に依存して完全に読み込まれ、表示されるCloudflareによって保護されているWebサイトの場合、Scrapeless Web Unlockerは専用のソリューションを提供します。
Scrapeless Universal APIはJavaScriptレンダリングと動的なインタラクションを可能にし、Cloudflareをバイパスするための効果的なツールとなります。
JavaScriptレンダリング
JavaScriptレンダリングは、動的に読み込まれたコンテンツとSPA(シングルページアプリケーション)の処理をサポートします。完全なブラウザ環境をサポートし、より複雑なページのインタラクションとレンダリング要件を処理します。
input.jsRender.enabled=trueを使用すると、リクエストにブラウザを使用します。
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"jsRender": {
"enabled": true
}
},
"proxy": {
"country": "US"
}
}JavaScript命令
幅広いJavaScript命令を提供し、Webページとの動的なインタラクションを可能にします。
これらの命令により、要素をクリックしたり、フォームに入力したり、フォームを送信したり、特定の要素が表示されるのを待機したりできます。これにより、「詳細はこちら」ボタンをクリックしたり、フォームを送信したりするなどのタスクに対して柔軟性があります。
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"jsRender": {
"enabled": true,
"instructions": [
{
"waitFor": [
".dynamic-content",
30000
]
// Wait for element
},
{
"click": [
"#load-more",
1000
]
// Click element
},
{
"fill": [
"#search-input",
"search term"
]
// Fill form
},
{
"keyboard": [
"press",
"Enter"
]
// Simulate key press
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// Execute custom JS
}
]
}
}
}チャレンジバイパスの例
次の例では、axiosを使用してScrapelessのWeb Unlockerサービスにリクエストを送信します。input.jsRender.enabledを有効にし、input.jsRender.instructionsパラメータのwaitFor命令を使用して、Cloudflareチャレンジをバイパスした後のページ上の要素を待機します。
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v2/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
jsRender: {
enabled: true,
instructions: [
{
waitFor: [
"main.page-content .challenge-info",
30000
]
}
]
}
}
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();上記のスクリプトを実行した後、コンソールでCloudflareチャレンジを正常にバイパスしたページのHTMLを確認できます。