Browser MCP
Scrapeless Browser MCP Serverは、ChatGPTやClaudeのようなモデル、CursorやWindsurfのようなツールを、以下のような幅広い外部機能にシームレスに接続します。
- ページレベルのナビゲーションとインタラクションのためのブラウザ自動化
- 動的でJavaScriptを多用するサイトをスクレイピング—HTML、Markdown、またはスクリーンショットとしてエクスポート
| MCPの種類 | 技術スタック | 利点 | 主要なエコシステム | 最適な用途 |
|---|---|---|---|---|
| Chrome DevTools MCP | Node.js / Puppeteer | 公式標準、堅牢、詳細なパフォーマンス分析ツール。 | 幅広い (Gemini, Copilot, Cursor) | CI/CD自動化、IDE横断ワークフロー、詳細なパフォーマンス監査。 |
| Playwright MCP | Node.js / Playwright | ピクセルではなくアクセシビリティツリーを使用。決定論的で、ビジョンなしでLLMに優しい。 | 幅広い (VS Code, Copilot) | 軽微なUI変更による破損が少ない、信頼性の高い構造化された自動化。 |
| Scrapeless Browser MCP | クラウドサービス | ローカルセットアップ不要、スケーラブルなクラウドブラウザ、複雑なサイトやアンチボット対策に対応。 | API駆動 (任意のクライアント) | 大規模な並列自動化タスク、強力なボット検出機能を持つウェブサイトとの連携。 |
サポートされているMCPツール
| Name | Description |
|---|---|
| browser_create | Scrapelessを使用してクラウドブラウザセッションを作成または再利用します。 |
| browser_close | クラウドブラウザを切断して現在のセッションを閉じます。 |
| browser_goto | ブラウザを指定されたURLに移動させます。 |
| browser_go_back | ブラウザの履歴を1つ前に戻ります。 |
| browser_go_forward | ブラウザの履歴を1つ先に進みます。 |
| browser_click | ページ上の特定の要素をクリックします。 |
| browser_type | 指定された入力フィールドにテキストを入力します。 |
| browser_press_key | キー押下をシミュレートします。 |
| browser_wait_for | 特定のページ要素が表示されるのを待ちます。 |
| browser_wait | 一定時間実行を一時停止します。 |
| browser_screenshot | 現在のページのスクリーンショットをキャプチャします。 |
| browser_get_html | 現在のページの完全なHTMLを取得します。 |
| browser_get_text | 現在のページからすべての表示可能なテキストを取得します。 |
| browser_scroll | ページの一番下までスクロールします。 |
| browser_scroll_to | 特定の要素を表示領域にスクロールします。 |
| scrape_html | URLをスクレイピングし、その完全なHTMLコンテンツを返します。 |
| scrape_markdown | URLをスクレイピングし、そのコンテンツをMarkdown形式で返します。 |
| scrape_screenshot | あらゆるウェブページの高品質なスクリーンショットをキャプチャします。 |
開始方法
Scrapeless APIキーの取得
Scrapelessにログインし、APIトークンを取得します。

MCPクライアントの構成
Scrapeless MCPサーバーは、StdioとStreamable HTTPの両方の転送モードをサポートしています。
🖥️ Stdio (ローカル実行)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Streamable HTTP (ホスト型APIモード)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
高度なオプション
オプションパラメータでブラウザセッションの動作をカスタマイズします。これらは環境変数 (Stdioの場合) またはHTTPヘッダー (Streamable HTTPの場合) を介して設定できます。
| Stdio (環境変数) | Streamable HTTP (HTTPヘッダー) | 説明 |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | セッションの継続性のために再利用可能なブラウザプロファイルIDを指定します。 |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | クッキー、ローカルストレージなどの永続ストレージを有効にします。 |
| BROWSER_SESSION_TTL | x-browser-session-ttl | 最大セッションタイムアウトを秒単位で定義します。セッションはこの非アクティブ期間の後、自動的に期限切れになります。 |
ユースケース
ウェブスクレイピングとデータ収集
- ECサイト監視: 製品ページを自動的に訪問し、価格、在庫状況、説明を収集します。
- 市場調査: ニュース、レビュー、または企業ページを一括スクレイピングして分析と比較を行います。
- コンテンツ集約: ページコンテンツ、投稿、コメントを抽出して一元的に収集します。
- リード生成: 企業ウェブサイトやディレクトリから連絡先情報や企業詳細を収集します。
テストと品質保証
- 機能検証: クリック、入力、要素待機を使用して、ページが期待通りに動作することを確認します。
- ユーザージャーニーテスト: 実際のユーザーインタラクション (入力、クリック、スクロール) をシミュレートしてワークフローを検証します。
- リグレッションテスト支援: 主要ページのスクリーンショットをキャプチャし、比較することでUIやコンテンツの変更を検出します。
タスクとワークフローの自動化
- フォーム入力: ウェブフォーム (例: 登録、アンケート) を自動的に完了して送信します。
- データキャプチャとレポート生成: 定期的にページデータを抽出し、分析用にHTMLまたはスクリーンショットとして保存します。
- 簡単な管理タスク: シミュレートされたクリックと入力を使用して、反復的なバックエンドまたはウェブベースの操作を自動化します。
ショーケース
ケース1: Claudeによるウェブインタラクションとデータ抽出の自動化
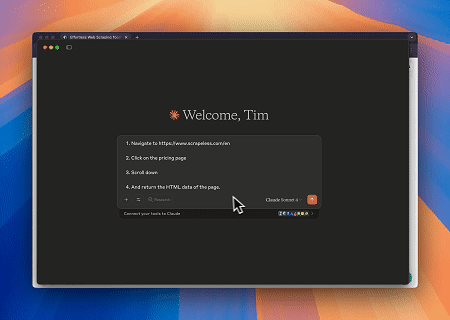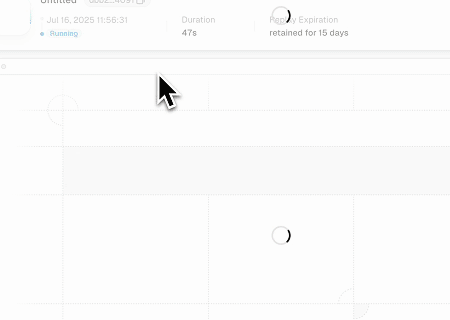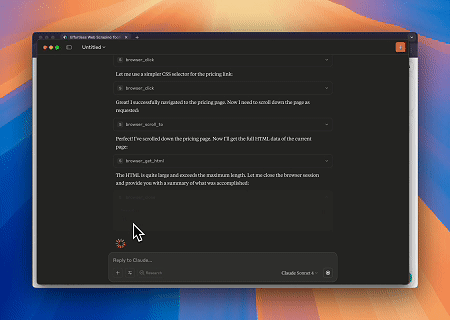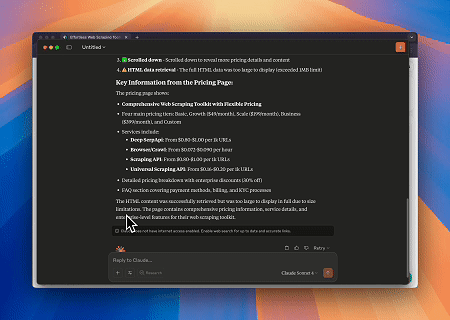
Browser MCPサーバーを使用することで、Claudeは会話型コマンドを通じて、ナビゲーション、クリック、スクロール、データスクレイピングなどの複雑なウェブ操作を実行でき、ライブセッションを通じてリアルタイムの実行プレビューも可能です。
ケース2: Cloudflareをバイパスしてターゲットページのコンテンツを取得する
Browser MCPサーバーを使用することで、Cloudflareによって保護されたページが自動的にアクセスされ、完了後にはページコンテンツが抽出されてMarkdown形式で返されます。
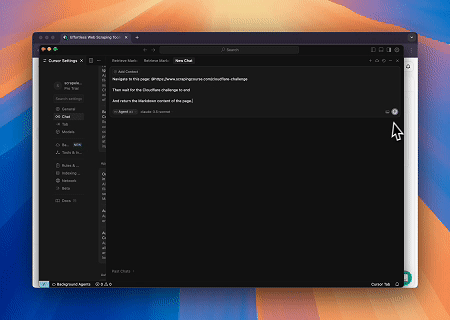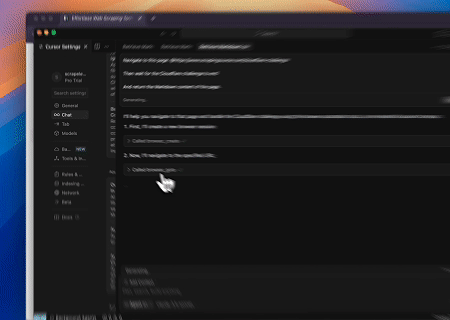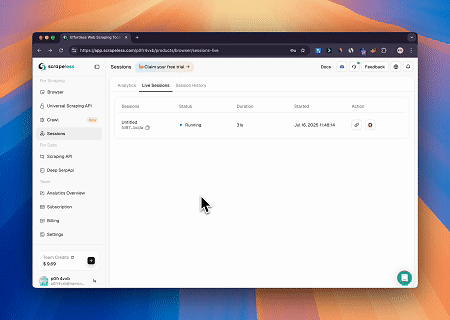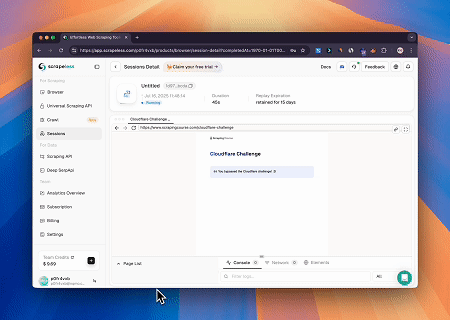
一つのクラウドブラウザ、無限の統合
Chrome DevTools MCP、Playwright MCP、Scrapeless Browser MCP はすべて、Scrapelessクラウドブラウザに接続するという一つの基盤を共有しています。
従来のローカルブラウザ自動化とは異なり、Scrapeless Browserは完全にクラウドで動作し、開発者やAIエージェントに比類のない柔軟性とスケーラビリティを提供します。
その真の強みは以下の点にあります。
- シームレスな統合: Puppeteer、Playwright、CDPと完全に互換性があり、既存のプロジェクトからの移行が1行のコードで簡単にできます。
- グローバルIPカバー範囲: 195カ国以上のレジデンシャル、ISP、および無制限のIPプールへのアクセスが、透明性があり費用対効果の高い料金 ($0.6–1.8/GB) で可能です。大規模なウェブデータ自動化に最適です。
- 分離されたプロファイル: 各タスクは専用の永続的な環境で実行され、セッションの分離、複数アカウントの管理、長期的な安定性を確保します。
- 無制限の同時スケーリング: 自動スケーリングインフラストラクチャにより、50〜1000以上のブラウザインスタンスを即座に起動できます。サーバーセットアップ不要、パフォーマンスボトルネックなし。
- 世界中のエッジノード: 複数のグローバルノードに展開することで、超低遅延と他のクラウドブラウザよりも2〜3倍速い起動を実現します。
- アンチ検出: reCAPTCHA、Cloudflare Turnstile、AWS WAFに対する組み込みソリューションにより、厳格な保護層の下でも中断のない自動化を保証します。
- ビジュアルデバッグ: ライブビューを介して、人間と機械の対話型デバッグとリアルタイムのプロキシトラフィック監視を実現します。セッション記録を通じてセッションをページごとに再生し、問題を迅速に特定し、操作を最適化します。
統合
Claudeデスクトップ
- Claudeデスクトップを開きます
設定→ツール→MCPサーバーに移動します- 「MCPサーバーを追加」をクリックします
- 上記の
StdioまたはStreamable HTTPの設定を貼り付けます - サーバーを保存して有効にします
- これでClaudeは、Scrapelessを使用してウェブクエリを発行し、コンテンツを抽出し、ページと対話できるようになります
Cursor IDE
- Cursorを開きます
Cmd + Shift + Pを押して、「Configure MCP Servers」を検索します- 上記の形式を使用してScrapeless MCP設定を追加します
- ファイルを保存し、Cursorを再起動します (必要に応じて)
- これでCursorに次のような質問ができるようになります。
- 「
このエラーの解決策をStackOverflowで検索して」 - 「
このページからHTMLをスクレイピングして」
- 「
- そして、CursorはバックグラウンドでScrapelessを使用します。