Crawl4AI
Crawl4AI は、大規模言語モデル (LLM)、AIエージェント、データパイプラインとのシームレスな統合を目的として設計された、オープンソースのウェブクローリングおよびスクレイピングツールです。高速でリアルタイムなデータ抽出を可能にしながら、柔軟でデプロイしやすい設計になっています。
AIを活用したウェブスクレイピングの主な機能:
- LLM向けに構築: Retrieval-Augmented Generation (RAG) とファインチューニングに最適化された構造化Markdownを生成します。
- 柔軟なブラウザ制御: セッション管理、プロキシ使用、カスタムフックをサポートします。
- ヒューリスティックなインテリジェンス: スマートなアルゴリズムを使用してデータ解析を最適化します。
- 完全オープンソース: APIキーは不要。Dockerおよびクラウドプラットフォーム経由でデプロイ可能です。
詳細については、公式ドキュメントをご覧ください。
Crawl4AIでScrapelessを使用する理由
Crawl4AIは、構造化されたウェブデータ抽出に優れ、LLM駆動の解析やパターンベースのスクレイピングをサポートします。しかし、以下のような高度なアンチボットメカニズムに対処する際には、依然として課題に直面する可能性があります。
- Cloudflare、AWS WAF、またはreCAPTCHAによってローカルブラウザがブロックされる
- 大規模な同時クローリング中のパフォーマンスボトルネック、ブラウザ起動の遅延
- 問題追跡を困難にする複雑なデバッグプロセス
Scrapelessクラウドブラウザは、これらの課題を完璧に解決します。
- ワンクリックでのアンチボット回避: reCAPTCHA、Cloudflare Turnstile/Challenge、AWS WAFなどを自動的に処理します。Crawl4AIの構造化抽出能力と組み合わせることで、成功率を大幅に向上させます。
- 無制限の同時スケーリング: タスクごとに50~1000以上のブラウザインスタンスを数秒で起動し、ローカルクローリングのパフォーマンス制限をなくし、Crawl4AIの効率を最大化します。
- 40%~80%のコスト削減: 同様のクラウドサービスと比較して、総コストがわずか20%~60%に削減されます。従量課金制により、小規模プロジェクトでも手頃な価格で利用できます。
- 視覚的なデバッグツール: セッションリプレイとライブURL監視を使用して、Crawl4AIタスクをリアルタイムで監視し、失敗の原因を迅速に特定し、デバッグのオーバーヘッドを削減します。
- ゼロコスト統合: Crawl4AIが使用するPlaywrightとネイティブに互換性があり、Crawl4AIをクラウドに接続するために必要なコードは1行だけで、コードのリファクタリングは不要です。
- エッジノードサービス (ENS): 複数のグローバルノードが、他のクラウドブラウザよりも2〜3倍高速な起動速度と安定性を提供し、Crawl4AIの実行を加速します。
- 隔離された環境と永続的なセッション: 各Scrapelessプロファイルは、独自の環境で永続的なログインとアイデンティティ隔離を持って実行され、セッション干渉を防ぎ、大規模な安定性を向上させます。
- 柔軟なフィンガープリント管理: Scrapelessはランダムなブラウザフィンガープリントを生成したり、カスタム設定を使用したりできるため、検出リスクを効果的に低減し、Crawl4AIの成功率を向上させます。
はじめに
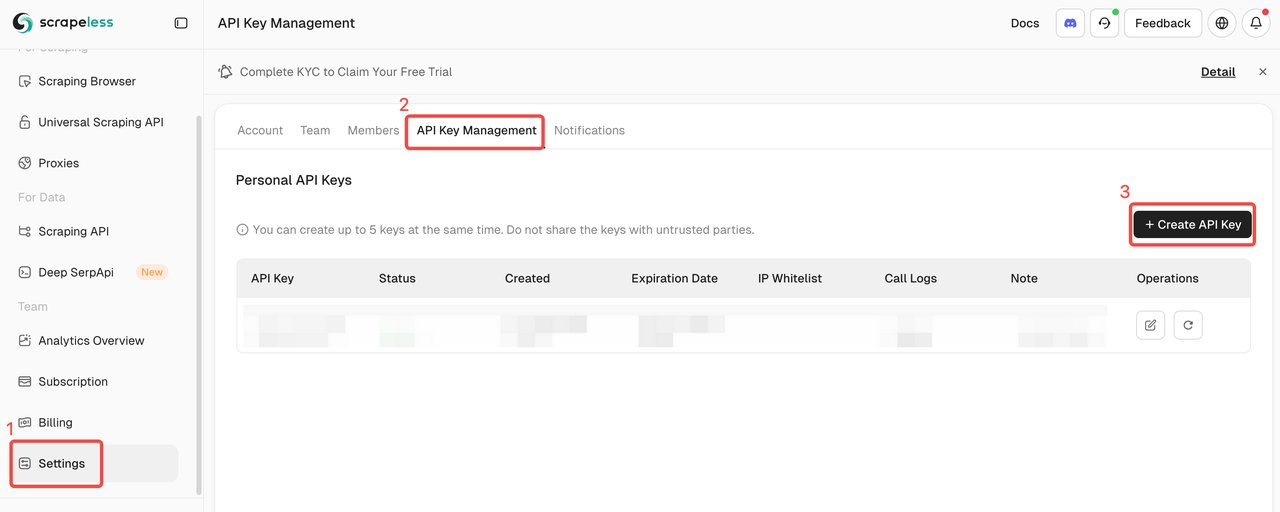
1. Scrapeless APIキーの取得
Scrapelessにログインして、APIトークンを取得します。
2. クイックスタート
以下の例は、Crawl4AIをScrapelessクラウドブラウザに素早く簡単に接続する方法を示しています。
その他の機能や詳細な手順については、はじめにを参照してください。
scrapeless_params = {
"token": "get your token from https://www.scrapeless.com",
"sessionName": "Scrapeless browser",
"sessionTTL": 1000,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url
)
)
設定後、Crawl4AIは**CDP (Chrome DevTools Protocol)**モードでScrapelessクラウドブラウザに接続し、ローカルのブラウザ環境なしでウェブスクレイピングを可能にします。ユーザーは、プロキシ、フィンガープリント、セッション再利用などの機能をさらに構成して、高並行および複雑なアンチボットシナリオの要求を満たすことができます。
3. グローバルな自動プロキシローテーション
Scrapelessは195カ国のレジデンシャルIPをサポートしています。ユーザーはproxycountryを使用してターゲット地域を設定でき、特定の場所からリクエストを送信できます。IPは自動的にローテーションされるため、ブロックを効果的に回避できます。
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Proxy Demo",
# Sets the target country/region for the proxy, sending requests via an IP address from that region. You can specify a country code (e.g., US for the United States, GB for the United Kingdom, ANY for any country). See country codes for all supported options."proxyCountry": "ANY",
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())
4. カスタムブラウザフィンガープリント
実際のユーザーの行動を模倣するために、Scrapelessはランダムに生成されたブラウザフィンガープリントをサポートし、カスタムフィンガープリントパラメータも許可します。これにより、ターゲットウェブサイトによる検出のリスクを効果的に低減します。
import json
import asyncio
from urllib.parse import quote, urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
# customize browser fingerprint
fingerprint = {
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36",
"platform": "Windows",
"screen": {
"width": 1280, "height": 1024
},
"localization": {
"languages": ["zh-HK", "en-US", "en"], "timezone": "Asia/Hong_Kong",
}
}
fingerprint_json = json.dumps(fingerprint)
encoded_fingerprint = quote(fingerprint_json)
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Fingerprint Demo",
"fingerprint": encoded_fingerprint,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())
5. プロファイルの再利用
Scrapelessは各プロファイルに独自の独立したブラウザ環境を割り当て、永続的なログインとアイデンティティの分離を可能にします。ユーザーはprofileIdを提供するだけで、以前のセッションを再利用できます。
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Profile Demo",
"profileId": "your profileId",# create profile on scrapeless
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())