Bypass do Cloudflare em raspagem web
Navegador de Raspagem e Cloudflare
Este documento técnico explica como usar as ferramentas Navegador de Raspagem Scrapeless e Desbloqueio Web Scrapeless para lidar com diversos desafios de segurança configurados pelo Cloudflare. Recursos-chave incluem contornar o Desafio JS do Cloudflare, o Turnstile do Cloudflare e executar a renderização de JavaScript para acessar conteúdo protegido pelo Cloudflare. Este documento fornecerá conhecimento de fundo relevante, introduções de recursos, etapas operacionais e explicações de exemplos de código.
Compreendendo os Desafios e Camadas de Segurança do Cloudflare
O Cloudflare, um serviço popular de segurança e desempenho na web, protege principalmente os sites de tráfego malicioso ou inesperado, como bots e scanners. Para isso, o Cloudflare implementa diversos mecanismos de detecção e defesa, incluindo, mas não se limitando a:
1. Desafio JS (Desafio JavaScript): Requer que o navegador do visitante execute um código JavaScript específico para verificar se é um ambiente de navegador legítimo com funcionalidade padrão.
2. Alternativa CAPTCHA Turnstile: Um mecanismo de verificação menos intrusivo para distinguir entre usuários humanos e bots.
3. Impressão digital do navegador: Coleta e analisa as características técnicas do navegador e do dispositivo (por exemplo, User-Agent, resolução de tela, fontes instaladas, plugins) para identificar e rastrear visitantes.
4. Limitação de taxa: Monitora e limita o número de solicitações de uma única fonte (por exemplo, endereço IP) dentro de um tempo específico para evitar força bruta ou abuso de recursos.
Essas camadas de segurança impedem que bibliotecas básicas de solicitações HTTP, scripts simples ou navegadores headless configurados incorretamente acessem sites protegidos pelo Cloudflare, resultando em falhas de verificação e negação de acesso.
Diferenças entre o Desafio JS do Cloudflare e Outros Desafios
A singularidade do Desafio JS do Cloudflare reside em seu método de verificação. Ele não requer apenas que os usuários concluam uma tarefa interativa simples (por exemplo, reconhecimento de imagem); ele exige que o ambiente do cliente (navegador) analise e execute com sucesso o código JavaScript gerado dinamicamente, muitas vezes ofuscado, do Cloudflare. Esse código executa verificações de ambiente, tarefas intensivas em computação ou outra lógica para verificar as capacidades de comportamento complexo do cliente, imitando um navegador real.
Superar o Desafio JS envolve gerar um token de autorização válido (geralmente na forma de um cookie cf_clearance). Esse token comprova que o cliente passou na verificação de capacidade de execução de JavaScript. Muitas ferramentas de automação não possuem um mecanismo de execução de JavaScript completo e uma simulação de ambiente de navegador realista, falhando, portanto, nesses desafios.
Contornando o Desafio JS do Cloudflare Usando o Navegador de Raspagem Scrapeless
O Navegador de Raspagem Scrapeless é projetado para lidar com medidas complexas de proteção de sites, incluindo o Desafio JS do Cloudflare.
Etapas e Exemplo de Código
Configuração do Ambiente
Criar uma Pasta de Projeto
Crie uma nova pasta para o projeto, por exemplo: scrapeless-bypass.
Navegue até a pasta no seu terminal:
cd path/to/scrapeless-bypassInicializar o Projeto Node.js
Execute o seguinte comando para criar um arquivo package.json:
npm init -yInstalar Dependências Necessárias
Instale o Puppeteer-core, que permite a conexão remota a instâncias do navegador:
npm install puppeteer-coreSe o Puppeteer ainda não estiver instalado no seu sistema, instale a versão completa:
npm install puppeteer puppeteer-coreObtenha e Configure Sua Chave de API Scrapeless.
Conecte-se e Certifique-se de que o CAPTCHA Foi Resolvido com Sucesso
O Scrapeless detecta e resolve automaticamente os CAPTCHAs ao se conectar ao navegador para acessar o site de destino. No entanto, precisamos garantir que o CAPTCHA tenha sido resolvido com sucesso. O Navegador de Raspagem Scrapeless estende o CDP (Chrome DevTools Protocol) padrão com um conjunto poderoso de recursos personalizados. O status do solucionador de CAPTCHA pode ser observado diretamente verificando os resultados retornados da API CDP:
Captcha.detected: CAPTCHA detectadoCaptcha.solveFinished: CAPTCHA resolvido com sucessoCaptcha.solveFailed: Falha na resolução do CAPTCHA
import puppeteer from "puppeteer-core";
import EventEmitter from 'events';
import { Scrapeless } from '@scrapeless-ai/sdk';
const emitter = new EventEmitter();
const client = new Scrapeless({ apiKey: 'API Key' });
const { browserWSEndpoint } = client.browser.create({
sessionName: 'sdk_test',
sessionTTL: 180,
proxyCountry: 'ANY',
sessionRecording: true,
fingerprint,
});
export async function example(url) {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null
});
console.log("Verbonden met Scrapeless browser");
try {
const page = await browser.newPage();
// Listen for captcha events
console.debug("addCaptchaListener: Start listening for captcha events");
await addCaptchaListener(page);
console.log("Navigated to URL:", url);
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 30000 });
console.log("onCaptchaFinished: Waiting for captcha solving to finish...");
await onCaptchaFinished()
// Screenshot for debugging
console.debug("Taking screenshot of the final page...");
await page.screenshot({ path: 'screenshot.png', fullPage: true });
} catch (error) {
console.error(error);
} finally {
await browser.close();
console.log("Browser closed");
}
}
async function addCaptchaListener(page) {
const client = await page.createCDPSession();
client.on("Captcha.detected", (msg) => {
console.debug("Captcha.detected: ", msg);
});
client.on("Captcha.solveFinished", async (msg) => {
console.debug("Captcha.solveFinished: ", msg);
emitter.emit("Captcha.solveFinished", msg);
client.removeAllListeners()
});
}
async function onCaptchaFinished(timeout = 60_000) {
return Promise.race([
new Promise((resolve) => {
emitter.on("Captcha.solveFinished", (msg) => {
resolve(msg);
});
}),
new Promise((_, reject) => setTimeout(() => reject('Timeout'), timeout))
])
}Este exemplo de fluxo de trabalho acessa o site de destino e confirma que o CAPTCHA foi resolvido com sucesso, ouvindo o evento Captcha.solveFinished do CDP. Finalmente, ele captura uma captura de tela da página para verificação.
Este exemplo define dois métodos principais:
addCaptchaListener: para ouvir eventos de CAPTCHA na sessão do navegadoronCaptchaFinished: para aguardar até que o CAPTCHA tenha sido resolvido
O código de exemplo acima pode ser usado para ouvir eventos CDP para três tipos comuns de CAPTCHA discutidos neste artigo: reCAPTCHA v2, Cloudflare Turnstile e Desafio de 5 segundos do Cloudflare.
Observe que o Desafio de 5 segundos do Cloudflare é um tanto especial. Às vezes, ele não aciona um desafio real, e confiar apenas na detecção de eventos CDP para o sucesso pode levar a timeouts. Portanto, aguardar que um elemento específico apareça na página após o desafio é uma solução mais estável.
Conectando ao WebSocket Sem Servidor Scrapeless
Scrapeless fornece uma conexão WebSocket, permitindo que o Puppeteer interaja diretamente com o navegador headless, contornando os desafios do Cloudflare.
O endereço de conexão WebSocket completo:
wss://browser.scrapeless.com/api/v2/browser?token=APIKey&sessionTTL=180&proxyCountry=ANYExemplo de Código: Contornando o Desafio do Cloudflare
Precisamos apenas do seguinte código para nos conectar ao serviço sem servidor do Scrapeless.
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com/api/v2';
const query = new URLSearchParams({
token: API_KEY,
sessionTTL: '180', // O ciclo de vida de uma sessão do navegador, em segundos
proxyCountry: 'GB', // País do agente
proxySessionId: 'test_session_id', // O id da sessão do proxy é usado para manter o ip do proxy inalterado. O tempo da sessão é de 3 minutos por padrão, com base na configuração proxySessionDuration.
proxySessionDuration: '5' // Tempo da sessão do agente, unidade minutos
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')Acessando Sites Protegidos pelo Cloudflare e Verificação de Captura de Tela
Em seguida, usamos o scrapeless browserless para acessar diretamente o site de teste do desafio do cloudflare e adicionar uma captura de tela, permitindo a verificação visual. Antes de tirar a captura de tela, observe que você precisa usar waitForSelector para aguardar os elementos na página, garantindo que o desafio do Cloudflare tenha sido contornado com sucesso.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// Aguardando elementos na página do site, garantindo que o desafio do Cloudflare tenha sido contornado com sucesso.
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
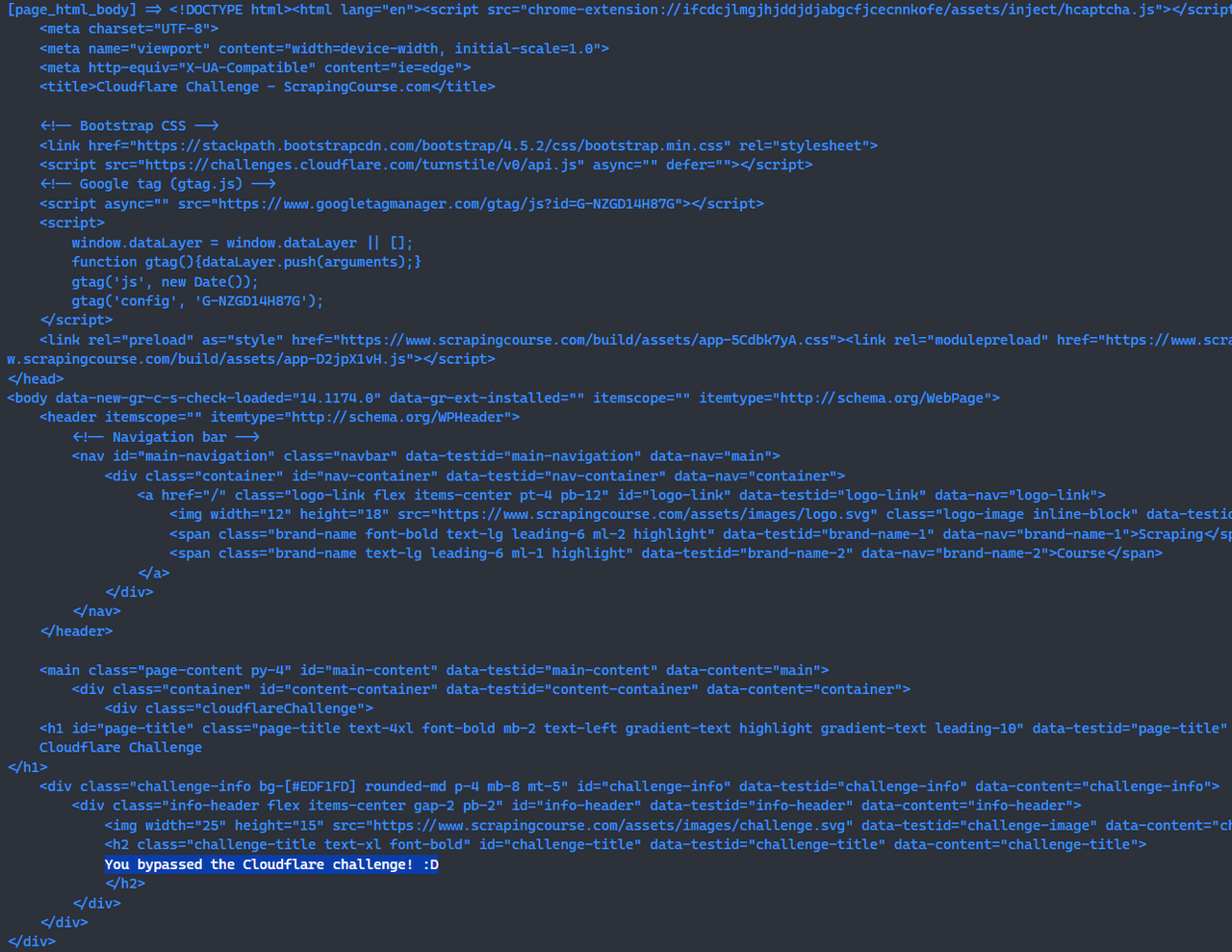
await page.screenshot({path: 'challenge-bypass.png'});Neste ponto, você contornou o desafio do Cloudflare usando o Scrapeless Browserless.

Recuperando o Cookie cf_clearance e o Cabeçalho
Depois de passar no desafio do Cloudflare, você pode recuperar os cabeçalhos da solicitação e o cookie cf_clearance da página bem-sucedida.
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueAtive a interceptação de solicitações para capturar cabeçalhos de solicitação e corresponder às solicitações da página após o desafio do Cloudflare.
await page.setRequestInterception(true);
page.on('request', request => {
// Corresponder às solicitações da página após o desafio do cloudflare
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});Contornando o Cloudflare Turnstile Usando o Navegador de Raspagem Scrapeless
O Navegador de Raspagem Scrapeless também lida com os desafios do Cloudflare Turnstile.
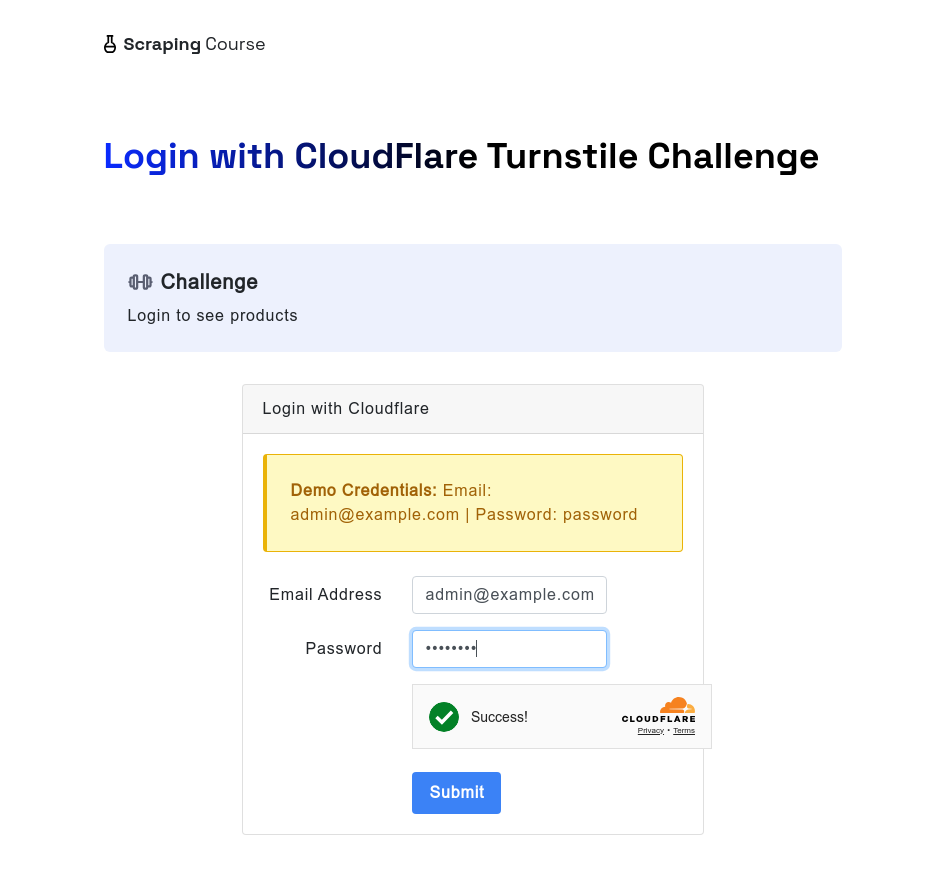
Da mesma forma, ao enfrentar o Cloudflare Turnstile, o navegador de raspagem sem servidor ainda pode lidar com ele automaticamente. O exemplo a seguir acessa o site de teste do cloudflare-turnstile. Após inserir o nome de usuário e a senha, ele usa o método waitForFunction para aguardar os dados de window.turnstile.getResponse(), garantindo que o desafio tenha sido contornado com sucesso. Em seguida, ele tira uma captura de tela e clica no botão de login para navegar para a próxima página.
Etapas e Exemplo de Código:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Aguardar o turnstile para desbloquear com sucesso
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });Depois de executar este script, você verá o efeito de desbloqueio por meio de capturas de tela.
Usando o Desbloqueio Web Scrapeless para Renderização de JavaScript
Para sites protegidos pelo Cloudflare onde o conteúdo principal depende da execução de JavaScript do lado do cliente para carregamento e exibição completos, o Desbloqueio Web Scrapeless fornece uma solução dedicada.
A API Universal Scrapeless permite a renderização e interação dinâmica de JavaScript, tornando-se uma ferramenta eficaz para contornar o Cloudflare.
Renderização de JavaScript
A renderização de JavaScript suporta o tratamento de conteúdo carregado dinamicamente e SPAs (Single-Page Applications). Ele suporta um ambiente de navegador completo, lidando com interações e requisitos de renderização de páginas mais complexos.
Com input.jsRender.enabled=true, usaremos o navegador para a solicitação
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"jsRender": {
"enabled": true
}
},
"proxy": {
"country": "US"
}
}Instruções de JavaScript
Fornece um amplo conjunto de instruções de JavaScript, permitindo interação dinâmica com páginas da web.
Essas instruções permitem clicar em elementos, preencher formulários, enviar formulários ou aguardar o aparecimento de elementos específicos, fornecendo flexibilidade para tarefas como clicar em um botão “Ler Mais” ou enviar um formulário.
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"jsRender": {
"enabled": true,
"instructions": [
{
"waitFor": [
".dynamic-content",
30000
]
// Aguardar elemento
},
{
"click": [
"#load-more",
1000
]
// Clicar no elemento
},
{
"fill": [
"#search-input",
"search term"
]
// Preencher o formulário
},
{
"keyboard": [
"press",
"Enter"
]
// Simular pressionamento de tecla
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// Executar JS personalizado
}
]
}
}
}Exemplo de Contorno de Desafio
O exemplo a seguir usa o axios para enviar uma solicitação ao serviço Desbloqueio Web do Scrapeless. Ele habilita input.jsRender.enabled e usa a instrução waitFor no parâmetro input.jsRender.instructions para aguardar um elemento na página após contornar o desafio do Cloudflare:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v2/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
jsRender: {
enabled: true,
instructions: [
{
waitFor: [
"main.page-content .challenge-info",
30000
]
}
]
}
}
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();Após executar o script acima, você poderá ver o HTML da página que contornou com sucesso o desafio do Cloudflare no console.