Browser MCP
Scrapeless Browser MCP Server conecta perfeitamente modelos como ChatGPT, Claude e ferramentas como Cursor e Windsurf a uma ampla gama de recursos externos, incluindo:
- Automação de navegador para navegação e interação ao nível da página
- Raspe sites dinâmicos e com muito JS—exporte como HTML, Markdown ou capturas de tela
| Tipo de MCP | Pilha Tecnológica | Vantagens | Ecossistema Principal | Melhor Para |
|---|---|---|---|---|
| Chrome DevTools MCP | Node.js / Puppeteer | Padrão oficial, robusto, ferramentas aprofundadas de análise de desempenho. | Ampla (Gemini, Copilot, Cursor) | Automação CI/CD, fluxos de trabalho entre IDEs e auditorias de desempenho aprofundadas. |
| Playwright MCP | Node.js / Playwright | Usa a árvore de acessibilidade em vez de pixels; determinístico e compatível com LLM sem visão. | Ampla (VS Code, Copilot) | Automação confiável e estruturada, menos propensa a quebras por pequenas alterações na interface do usuário. |
| Scrapeless Browser MCP | Serviço em Nuvem | Configuração local zero, navegadores em nuvem escaláveis, lida com sites complexos e medidas anti-bot. | Orientado por API (Qualquer cliente) | Tarefas de automação em larga escala e paralelas, e interação com sites que possuem forte detecção de bots. |
Ferramentas MCP Suportadas
| Nome | Descrição |
|---|---|
| browser_create | Cria ou reutiliza uma sessão de navegador em nuvem usando Scrapeless. |
| browser_close | Fecha a sessão atual desconectando o navegador em nuvem. |
| browser_goto | Navega o navegador para uma URL especificada. |
| browser_go_back | Volta um passo no histórico do navegador. |
| browser_go_forward | Avança um passo no histórico do navegador. |
| browser_click | Clica em um elemento específico na página. |
| browser_type | Digita texto em um campo de entrada especificado. |
| browser_press_key | Simula o pressionar de uma tecla. |
| browser_wait_for | Espera por um elemento específico da página aparecer. |
| browser_wait | Pausa a execução por uma duração fixa. |
| browser_screenshot | Captura uma captura de tela da página atual. |
| browser_get_html | Obtém o HTML completo da página atual. |
| browser_get_text | Obtém todo o texto visível da página atual. |
| browser_scroll | Rola até o final da página. |
| browser_scroll_to | Rola um elemento específico para a visualização. |
| scrape_html | Raspa uma URL e retorna seu conteúdo HTML completo. |
| scrape_markdown | Raspa uma URL e retorna seu conteúdo como Markdown. |
| scrape_screenshot | Captura uma captura de tela de alta qualidade de qualquer página web. |
Primeiros Passos
Obtenha Sua Chave de API Scrapeless
Faça login no Scrapeless e obtenha seu Token de API.

Configure Seu Cliente MCP
O Servidor MCP Scrapeless suporta ambos os modos de transporte Stdio e HTTP Transmitível.
🖥️ Stdio (Execução Local)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 HTTP Transmitível (Modo API Hospedado)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Opções Avançadas
Personalize o comportamento da sessão do navegador com parâmetros opcionais. Estes podem ser definidos via variáveis de ambiente (para Stdio) ou cabeçalhos HTTP (para HTTP Transmitível):
| Stdio (Variável de Ambiente) | HTTP Transmitível (Cabeçalho HTTP) | Descrição |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Especifica um ID de perfil de navegador reutilizável para continuidade da sessão. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Habilita armazenamento persistente para cookies, armazenamento local, etc. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Define o tempo limite máximo da sessão em segundos. A sessão irá expirar automaticamente após esta duração de inatividade. |
Casos de Uso
Raspagem da Web e Coleta de Dados
- Monitoramento de E-commerce: Visite automaticamente páginas de produtos para coletar preços, status de estoque e descrições.
- Pesquisa de Mercado: Raspe em lote notícias, avaliações ou páginas de empresas para análise e comparação.
- Agregação de Conteúdo: Extraia conteúdo de página, posts e comentários para coleta centralizada.
- Geração de Leads: Reúna informações de contato e detalhes da empresa de sites corporativos ou diretórios.
Testes e Garantia de Qualidade
- Verificação de Função: Use cliques, digitação e esperas por elementos para garantir que as páginas se comportem como esperado.
- Teste de Jornada do Usuário: Simule interações reais do usuário (digitar, clicar, rolar) para validar fluxos de trabalho.
- Suporte a Testes de Regressão: Capture capturas de tela de páginas-chave e compare para detectar alterações na interface do usuário ou no conteúdo.
Automação de Tarefas e Fluxos de Trabalho
- Preenchimento de Formulários: Preencha e envie automaticamente formulários web (por exemplo, registros, pesquisas).
- Captura de Dados e Geração de Relatórios: Extraia periodicamente dados de páginas e salve como HTML ou capturas de tela para análise.
- Tarefas Administrativas Simples: Automatize operações repetitivas de backend ou baseadas na web usando cliques e digitação simulados.
Demonstração
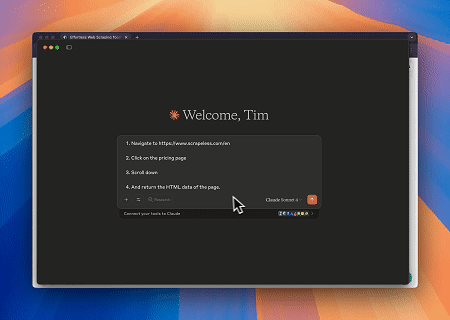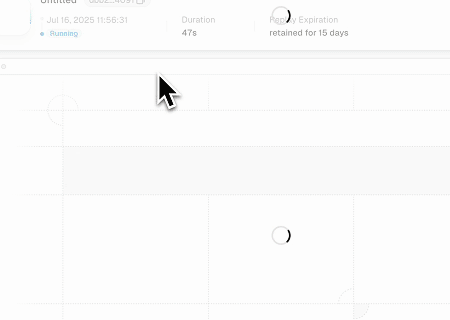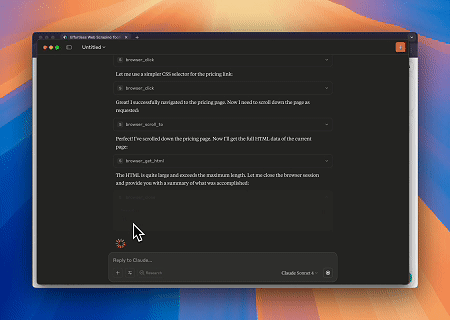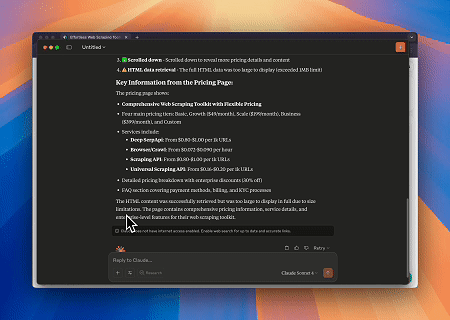
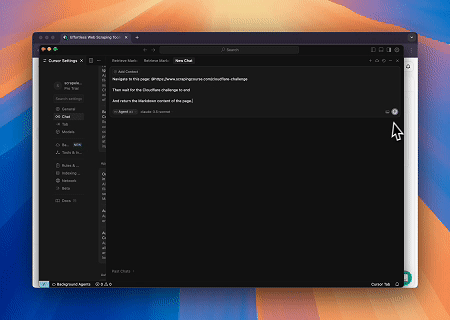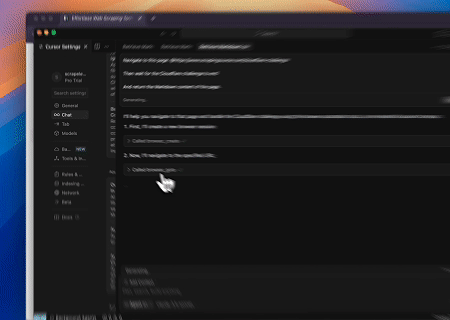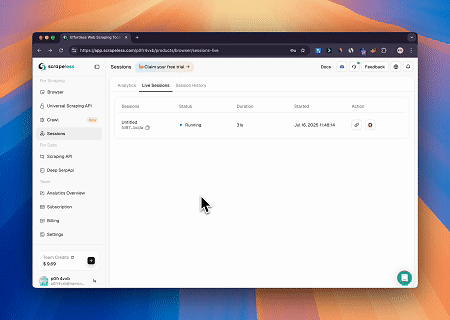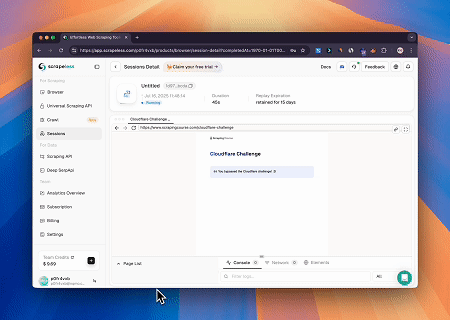
Caso 1: Automação de Interação Web e Extração de Dados com Claude
Usando o Browser MCP Server, Claude pode realizar operações web complexas—como navegação, cliques, rolagem e raspagem de dados—através de comandos conversacionais, com pré-visualização da execução em tempo real via sessões ao vivo.
Caso 2: Contornando o Cloudflare para Recuperar Conteúdo da Página Alvo
Usando o Browser MCP Server, páginas protegidas pelo Cloudflare são acessadas automaticamente e, após a conclusão, o conteúdo da página é extraído e retornado no formato Markdown.
Um Navegador em Nuvem, Integrações Infinitas
Chrome DevTools MCP, Playwright MCP e Scrapeless Browser MCP — compartilham uma base: todos se conectam ao Scrapeless Cloud Browser.
Ao contrário da automação de navegador local tradicional, o Scrapeless Browser é executado inteiramente na ****nuvem, oferecendo flexibilidade e escalabilidade incomparáveis para desenvolvedores e agentes de IA.
Aqui está o que o torna verdadeiramente poderoso:
- Integração Perfeita: Totalmente compatível com Puppeteer, Playwright e CDP, permitindo migração sem esforço de projetos existentes com uma única linha de código.
- Cobertura Global de IP: Acesso a pools de IP residenciais, de ISP e ilimitados em mais de 195 países, a uma taxa transparente e econômica ($0.6–1.8/GB). Perfeito para automação de dados web em larga escala.
- Perfis Isolados: Cada tarefa é executada em um ambiente dedicado e persistente, garantindo isolamento de sessão, gerenciamento de múltiplas contas e estabilidade a longo prazo.
- Escalonamento Concorrente Ilimitado: Inicie instantaneamente mais de 50–1000 instâncias de navegador com infraestrutura de autoescalonamento — sem configuração de servidor, sem gargalo de desempenho.
- Nós de Borda em Todo o Mundo: Implante em múltiplos nós globais para latência ultrabaixa e inicialização 2–3 vezes mais rápida do que outros navegadores em nuvem.
- Anti-Detecção: Soluções integradas para reCAPTCHA, Cloudflare Turnstile e AWS WAF, garantindo automação ininterrupta mesmo sob camadas de proteção rigorosas.
- Depuração Visual: Obtenha depuração interativa humano-máquina e monitoramento de tráfego de proxy em tempo real via Live View. Reproduza sessões página por página através de Gravações de Sessão para identificar rapidamente problemas e otimizar operações.
Integrações
Claude Desktop
- Abra o Claude Desktop
- Navegue para:
Configurações→Ferramentas→Servidores MCP - Clique em “Adicionar Servidor MCP”
- Cole a configuração
StdioouHTTP Transmitívelacima - Salve e ative o servidor
- Claude agora será capaz de emitir consultas web, extrair conteúdo e interagir com páginas usando Scrapeless
Cursor IDE
- Abra o Cursor
- Pressione
Cmd + Shift + Pe procure por:Configurar Servidores MCP - Adicione a configuração Scrapeless MCP usando o formato acima
- Salve o arquivo e reinicie o Cursor (se necessário)
- Agora você pode perguntar ao Cursor coisas como:
"Procure no StackOverflow por uma solução para este erro""Raspe o HTML desta página"
- E ele usará o Scrapeless em segundo plano.