Vượt qua Cloudflare trong web scraping
Trình duyệt Scraping và Cloudflare
Tài liệu kỹ thuật này giải thích cách sử dụng các công cụ Trình duyệt Scrapeless Scraping và Scrapeless Web Unlocker để xử lý các thách thức bảo mật khác nhau được thiết lập bởi Cloudflare. Các tính năng chính bao gồm bỏ qua Cloudflare JS Challenge, Cloudflare Turnstile và thực hiện rendering JavaScript để truy cập nội dung được bảo vệ bởi Cloudflare. Tài liệu này sẽ cung cấp kiến thức nền tảng liên quan, giới thiệu tính năng, các bước hoạt động và giải thích ví dụ mã.
Hiểu về các thách thức và lớp bảo mật của Cloudflare
Cloudflare, một dịch vụ bảo mật và hiệu năng web phổ biến, chủ yếu bảo vệ các trang web khỏi lưu lượng truy cập độc hại hoặc không mong muốn, chẳng hạn như bot và máy quét. Vì mục đích này, Cloudflare thực hiện nhiều cơ chế phát hiện và phòng thủ, bao gồm nhưng không giới hạn ở:
1. JS Challenge (Thử thách JavaScript): Yêu cầu trình duyệt của người truy cập thực thi mã JavaScript cụ thể để xác minh đó là môi trường trình duyệt hợp lệ với chức năng tiêu chuẩn.
2. Turnstile CAPTCHA Alternative: Một cơ chế xác minh ít gây khó chịu hơn để phân biệt giữa người dùng và bot.
3. Browser Fingerprinting: Thu thập và phân tích các đặc điểm kỹ thuật của trình duyệt và thiết bị (ví dụ: User-Agent, độ phân giải màn hình, phông chữ đã cài đặt, plugin) để xác định và theo dõi người truy cập.
4. Rate Limiting: Giám sát và giới hạn số lượng yêu cầu từ một nguồn duy nhất (ví dụ: địa chỉ IP) trong một khoảng thời gian cụ thể để ngăn chặn brute-forcing hoặc lạm dụng tài nguyên.
Các lớp bảo mật này ngăn chặn các thư viện yêu cầu HTTP cơ bản, các script đơn giản hoặc các trình duyệt headless được cấu hình không chính xác truy cập vào các trang web được bảo vệ bởi Cloudflare, dẫn đến lỗi xác minh và từ chối truy cập.
Sự khác biệt giữa Cloudflare JS Challenge và các thách thức khác
Sự độc đáo của Cloudflare JS Challenge nằm ở phương pháp xác minh của nó. Nó không chỉ yêu cầu người dùng hoàn thành một nhiệm vụ tương tác đơn giản (ví dụ: nhận dạng hình ảnh); nó yêu cầu môi trường client (trình duyệt) phân tích cú pháp và thực thi thành công mã JavaScript được tạo động, thường bị mã hóa, từ Cloudflare. Mã này thực hiện kiểm tra môi trường, các tác vụ tính toán chuyên sâu hoặc logic khác để xác minh khả năng hoạt động phức tạp của client, bắt chước một trình duyệt thực.
Việc vượt qua JS Challenge thành công liên quan đến việc tạo một token xóa hợp lệ (thường ở dạng cookie cf_clearance). Token này chứng minh rằng client đã vượt qua xác minh khả năng thực thi JavaScript. Nhiều công cụ tự động hóa thiếu một công cụ thực thi JavaScript hoàn chỉnh và mô phỏng môi trường trình duyệt thực tế, do đó không vượt qua được những thách thức như vậy.
Vượt qua Cloudflare JS Challenge bằng Trình duyệt Scrapeless Scraping
Trình duyệt Scrapeless Scraping được thiết kế để xử lý các biện pháp bảo vệ trang web phức tạp, bao gồm cả Cloudflare JS Challenge.
Các bước và ví dụ mã
Thiết lập môi trường
Tạo một thư mục Project
Tạo một thư mục mới cho dự án, ví dụ: scrapeless-bypass.
Điều hướng đến thư mục trong terminal của bạn:
cd path/to/scrapeless-bypassKhởi tạo dự án Node.js
Chạy lệnh sau để tạo tệp package.json:
npm init -yCài đặt các phụ thuộc cần thiết
Cài đặt Puppeteer-core, cho phép kết nối từ xa với các phiên bản trình duyệt:
npm install puppeteer-coreNếu Puppeteer chưa được cài đặt trên hệ thống của bạn, hãy cài đặt phiên bản đầy đủ:
npm install puppeteer puppeteer-coreThu thập và cấu hình API Key Scrapeless của bạn.
Kết nối và đảm bảo CAPTCHA được giải quyết thành công
Scrapeless tự động phát hiện và giải quyết CAPTCHA khi kết nối với trình duyệt để truy cập trang web mục tiêu. Tuy nhiên, chúng ta cần đảm bảo CAPTCHA được giải quyết thành công. Trình duyệt Scrapeless Scraping mở rộng giao thức CDP (Chrome DevTools Protocol) tiêu chuẩn với một tập hợp các khả năng tùy chỉnh mạnh mẽ. Trạng thái của trình giải quyết CAPTCHA có thể được quan sát trực tiếp bằng cách kiểm tra kết quả trả về từ API CDP:
Captcha.detected: CAPTCHA được phát hiệnCaptcha.solveFinished: CAPTCHA được giải quyết thành côngCaptcha.solveFailed: CAPTCHA giải quyết thất bại
import puppeteer from "puppeteer-core";
import EventEmitter from 'events';
import { Scrapeless } from '@scrapeless-ai/sdk';
const emitter = new EventEmitter();
const client = new Scrapeless({ apiKey: 'API Key' });
const { browserWSEndpoint } = client.browser.create({
sessionName: 'sdk_test',
sessionTTL: 180,
proxyCountry: 'ANY',
sessionRecording: true,
fingerprint,
});
export async function example(url) {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null
});
console.log("Verbonden met Scrapeless browser");
try {
const page = await browser.newPage();
// Listen for captcha events
console.debug("addCaptchaListener: Start listening for captcha events");
await addCaptchaListener(page);
console.log("Navigated to URL:", url);
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 30000 });
console.log("onCaptchaFinished: Waiting for captcha solving to finish...");
await onCaptchaFinished()
// Screenshot for debugging
console.debug("Taking screenshot of the final page...");
await page.screenshot({ path: 'screenshot.png', fullPage: true });
} catch (error) {
console.error(error);
} finally {
await browser.close();
console.log("Browser closed");
}
}
async function addCaptchaListener(page) {
const client = await page.createCDPSession();
client.on("Captcha.detected", (msg) => {
console.debug("Captcha.detected: ", msg);
});
client.on("Captcha.solveFinished", async (msg) => {
console.debug("Captcha.solveFinished: ", msg);
emitter.emit("Captcha.solveFinished", msg);
client.removeAllListeners()
});
}
async function onCaptchaFinished(timeout = 60_000) {
return Promise.race([
new Promise((resolve) => {
emitter.on("Captcha.solveFinished", (msg) => {
resolve(msg);
});
}),
new Promise((_, reject) => setTimeout(() => reject('Timeout'), timeout))
])
}Ví dụ quy trình công việc này truy cập trang web mục tiêu và xác nhận CAPTCHA đã được giải quyết thành công bằng cách lắng nghe sự kiện Captcha.solveFinished CDP. Cuối cùng, nó chụp ảnh màn hình của trang để xác minh.
Ví dụ này định nghĩa hai phương thức chính:
addCaptchaListener: để lắng nghe các sự kiện CAPTCHA trong phiên trình duyệtonCaptchaFinished: để chờ cho đến khi CAPTCHA được giải quyết
Mã ví dụ trên có thể được sử dụng để lắng nghe các sự kiện CDP cho ba loại CAPTCHA phổ biến được thảo luận trong bài viết này: reCAPTCHA v2, Cloudflare Turnstile và Cloudflare 5s Challenge.
Lưu ý rằng Cloudflare 5s Challenge hơi đặc biệt. Đôi khi nó không kích hoạt một thách thức thực tế, và chỉ dựa vào phát hiện sự kiện CDP để thành công có thể dẫn đến hết thời gian. Do đó, chờ một phần tử cụ thể xuất hiện trên trang sau khi thách thức là một giải pháp ổn định hơn.
Kết nối với Scrapeless Browserless WebSocket
Scrapeless cung cấp kết nối WebSocket, cho phép Puppeteer tương tác trực tiếp với trình duyệt headless, bỏ qua các thách thức Cloudflare.
Địa chỉ kết nối WebSocket đầy đủ:
wss://browser.scrapeless.com/api/v2/browser?token=APIKey&sessionTTL=180&proxyCountry=ANYVí dụ mã: Bỏ qua thách thức Cloudflare
Chúng ta chỉ cần mã sau để kết nối với dịch vụ browserless của Scrapeless.
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com/api/v2';
const query = new URLSearchParams({
token: API_KEY,
sessionTTL: '180', // Thời gian tồn tại của một phiên trình duyệt, tính bằng giây
proxyCountry: 'GB', // Quốc gia của Agent
proxySessionId: 'test_session_id', // ID phiên proxy được sử dụng để giữ nguyên IP proxy. Thời gian phiên là 3 phút theo mặc định, dựa trên cài đặt proxySessionDuration.
proxySessionDuration: '5' // Thời gian phiên của Agent, đơn vị phút
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')Truy cập các trang web được bảo vệ bởi Cloudflare và xác minh ảnh chụp màn hình
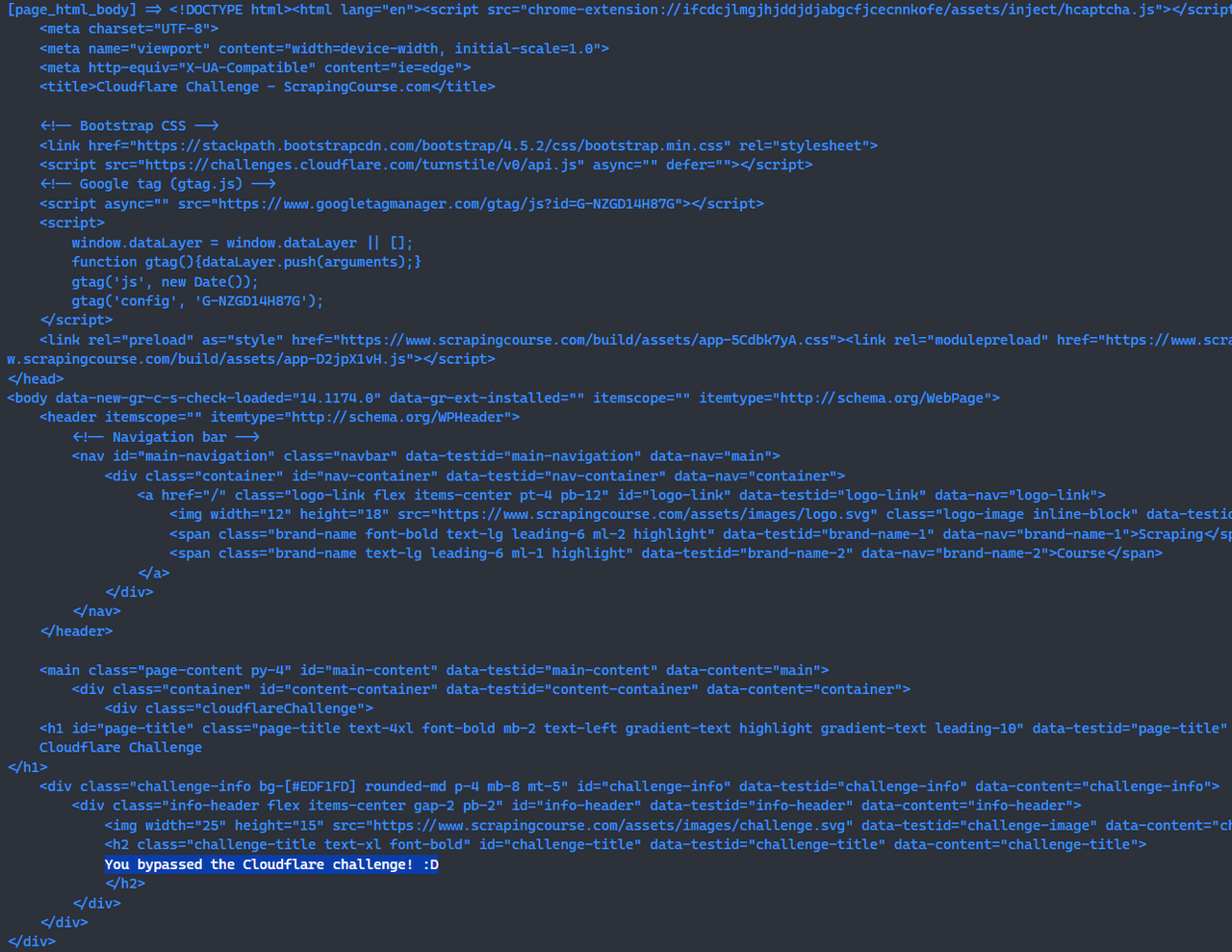
Tiếp theo, chúng ta sử dụng scrapeless browserless để truy cập trực tiếp vào trang kiểm thử cloudflare-challenge và thêm ảnh chụp màn hình, cho phép xác minh trực quan. Trước khi chụp ảnh màn hình, lưu ý rằng bạn cần sử dụng waitForSelector để chờ các phần tử trên trang, đảm bảo thách thức Cloudflare đã được bỏ qua thành công.
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// Bằng cách chờ các phần tử trong trang web, đảm bảo rằng thách thức Cloudflare đã được bỏ qua thành công.
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
await page.screenshot({path: 'challenge-bypass.png'});Tại thời điểm này, bạn đã bỏ qua thách thức Cloudflare bằng cách sử dụng Scrapeless Browserless.

Lấy cookie và tiêu đề cf_clearance
Sau khi vượt qua thách thức Cloudflare, bạn có thể lấy tiêu đề yêu cầu và cookie cf_clearance từ trang thành công.
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.valueBật chặn yêu cầu để chụp tiêu đề yêu cầu và khớp các yêu cầu trang sau khi thách thức Cloudflare.
await page.setRequestInterception(true);
page.on('request', request => {
// Khớp các yêu cầu trang sau thách thức cloudflare
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});Vượt qua Cloudflare Turnstile bằng Trình duyệt Scrapeless Scraping
Trình duyệt Scrapeless Scraping cũng xử lý các thách thức Cloudflare Turnstile.
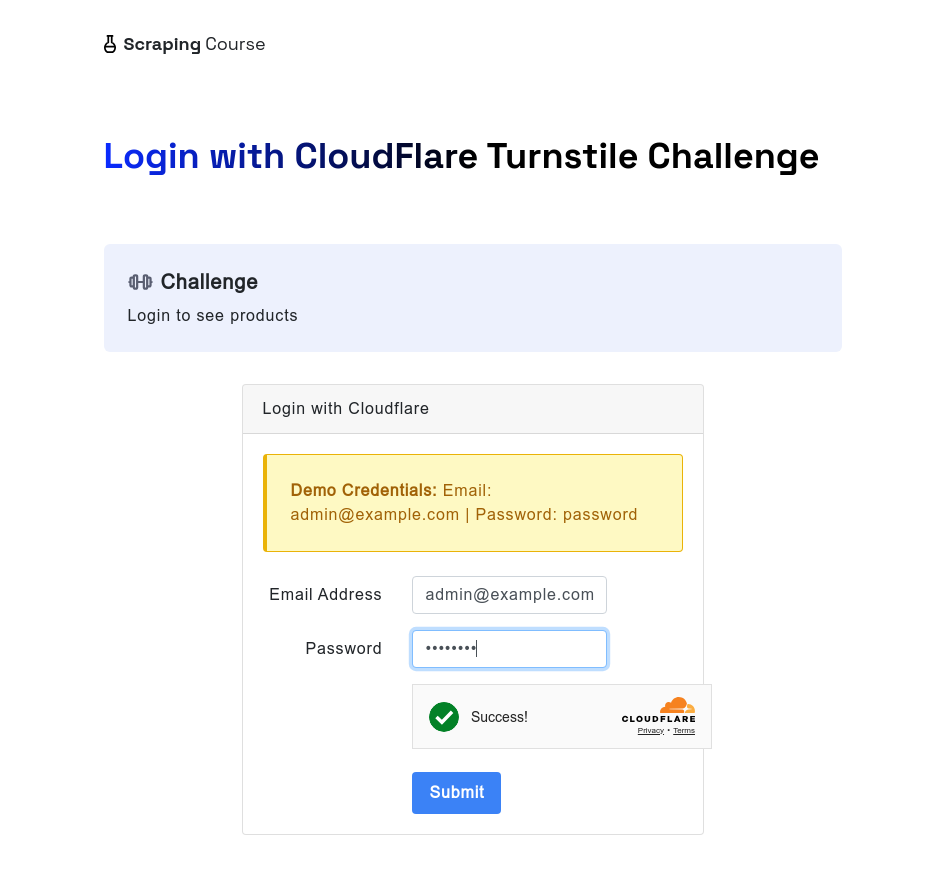
Tương tự, khi gặp Cloudflare Turnstile, trình duyệt scraping browserless vẫn có thể xử lý nó tự động. Ví dụ sau truy cập vào trang kiểm thử cloudflare-turnstile. Sau khi nhập tên người dùng và mật khẩu, nó sử dụng phương thức waitForFunction để chờ dữ liệu từ window.turnstile.getResponse(), đảm bảo thách thức đã được bỏ qua thành công. Sau đó, nó chụp ảnh màn hình và nhấp vào nút đăng nhập để điều hướng đến trang tiếp theo.
Các bước và ví dụ mã:
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/login/cf-turnstile', { waitUntil: 'domcontentloaded' });
await page.locator('input[type="email"]').fill('admin@example.com')
await page.locator('input[type="password"]').fill('password')
// Chờ turnstile mở khóa thành công
await page.waitForFunction(() => {
return window.turnstile && window.turnstile.getResponse();
});
await page.screenshot({ path: 'challenge-bypass-success.png' });
await page.locator('button[type="submit"]').click()
await page.waitForNavigation()
await page.screenshot({ path: 'next-page.png' });Sau khi chạy script này, bạn sẽ thấy hiệu ứng mở khóa thông qua ảnh chụp màn hình.
Sử dụng Scrapeless Web Unlocker để rendering JavaScript
Đối với các trang web được bảo vệ bởi Cloudflare, nơi nội dung cốt lõi dựa vào việc thực thi JavaScript phía client để tải và hiển thị hoàn chỉnh, Scrapeless Web Unlocker cung cấp một giải pháp chuyên dụng.
Scrapeless Universal API cho phép rendering JavaScript và tương tác động, làm cho nó trở thành một công cụ hiệu quả để bỏ qua Cloudflare.
Rendering JavaScript
Rendering JavaScript hỗ trợ xử lý nội dung được tải động và SPA (Single-Page Applications). Nó hỗ trợ môi trường trình duyệt đầy đủ, xử lý các tương tác trang và yêu cầu rendering phức tạp hơn.
Với input.jsRender.enabled=true, chúng ta sẽ sử dụng trình duyệt cho yêu cầu
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"jsRender": {
"enabled": true
}
},
"proxy": {
"country": "US"
}
}Hướng dẫn JavaScript
Cung cấp một tập hợp rộng các hướng dẫn JavaScript, cho phép tương tác động với các trang web.
Các hướng dẫn này cho phép nhấp vào các phần tử, điền vào biểu mẫu, gửi biểu mẫu hoặc chờ các phần tử cụ thể xuất hiện, cung cấp tính linh hoạt cho các tác vụ như nhấp vào nút “Đọc thêm” hoặc gửi biểu mẫu.
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"jsRender": {
"enabled": true,
"instructions": [
{
"waitFor": [
".dynamic-content",
30000
]
// Chờ phần tử
},
{
"click": [
"#load-more",
1000
]
// Nhấp vào phần tử
},
{
"fill": [
"#search-input",
"search term"
]
// Điền vào biểu mẫu
},
{
"keyboard": [
"press",
"Enter"
]
// Mô phỏng nhấn phím
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// Thực thi JS tùy chỉnh
}
]
}
}
}Ví dụ bỏ qua thách thức
Ví dụ sau sử dụng axios để gửi yêu cầu đến dịch vụ Scrapeless Web Unlocker. Nó bật input.jsRender.enabled và sử dụng hướng dẫn waitFor trong tham số input.jsRender.instructions để chờ một phần tử trên trang sau khi bỏ qua thách thức Cloudflare:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v2/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
jsRender: {
enabled: true,
instructions: [
{
waitFor: [
"main.page-content .challenge-info",
30000
]
}
]
}
}
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();Sau khi chạy script ở trên, bạn sẽ có thể thấy HTML của trang đã bỏ qua thách thức Cloudflare thành công trong console.