Crawl4AI
Crawl4AI là một công cụ thu thập và trích xuất dữ liệu web mã nguồn mở được thiết kế để tích hợp liền mạch với Các mô hình ngôn ngữ lớn (LLM), Tác nhân AI và các quy trình dữ liệu. Nó cho phép trích xuất dữ liệu tốc độ cao, thời gian thực đồng thời vẫn linh hoạt và dễ triển khai.
Các tính năng chính cho việc thu thập dữ liệu web bằng AI bao gồm:
- Được xây dựng cho LLM: Tạo ra Markdown có cấu trúc được tối ưu hóa cho Tạo sinh tăng cường truy xuất (RAG) và tinh chỉnh.
- Kiểm soát trình duyệt linh hoạt: Hỗ trợ quản lý phiên, sử dụng proxy và các hook tùy chỉnh.
- Trí tuệ theo kinh nghiệm: Sử dụng các thuật toán thông minh để tối ưu hóa việc phân tích dữ liệu.
- Hoàn toàn mã nguồn mở: Không yêu cầu khóa API; có thể triển khai qua Docker và các nền tảng đám mây.
Tìm hiểu thêm trong tài liệu chính thức.
Tại sao nên sử dụng Scrapeless với Crawl4AI?
Crawl4AI vượt trội trong việc trích xuất dữ liệu web có cấu trúc và hỗ trợ phân tích dữ liệu dựa trên LLM cùng với việc thu thập dữ liệu dựa trên mẫu. Tuy nhiên, nó vẫn có thể đối mặt với những thách thức khi xử lý các cơ chế chống bot tiên tiến, chẳng hạn như:
- Các trình duyệt cục bộ bị chặn bởi Cloudflare, AWS WAF hoặc reCAPTCHA
- Nút thắt cổ chai về hiệu suất trong quá trình thu thập dữ liệu đồng thời quy mô lớn, với thời gian khởi động trình duyệt chậm
- Các quy trình gỡ lỗi phức tạp gây khó khăn trong việc theo dõi sự cố
Trình duyệt đám mây Scrapeless giải quyết hoàn hảo những vấn đề này:
- Bỏ qua cơ chế chống bot chỉ với một cú nhấp chuột: Tự động xử lý reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF và nhiều hơn nữa. Kết hợp với sức mạnh trích xuất cấu trúc của Crawl4AI, nó tăng đáng kể tỷ lệ thành công.
- Khả năng mở rộng đồng thời không giới hạn: Khởi chạy 50–1000+ phiên trình duyệt cho mỗi tác vụ trong vòng vài giây, loại bỏ giới hạn hiệu suất thu thập dữ liệu cục bộ và tối đa hóa hiệu quả của Crawl4AI.
- Giảm 40%–80% chi phí: So với các dịch vụ đám mây tương tự, tổng chi phí giảm xuống chỉ còn 20%–60%. Mô hình giá trả theo mức sử dụng giúp nó trở nên phải chăng ngay cả đối với các dự án nhỏ.
- Công cụ gỡ lỗi trực quan: Sử dụng Phát lại phiên và Giám sát URL trực tiếp để xem các tác vụ của Crawl4AI trong thời gian thực, nhanh chóng xác định nguyên nhân lỗi và giảm chi phí gỡ lỗi.
- Tích hợp không tốn chi phí: Tương thích nguyên bản với Playwright (được Crawl4AI sử dụng), chỉ yêu cầu một dòng mã để kết nối Crawl4AI với đám mây — không cần cấu trúc lại mã.
- Dịch vụ Nút biên (ENS): Nhiều nút toàn cầu cung cấp tốc độ khởi động và độ ổn định nhanh hơn 2–3 lần so với các trình duyệt đám mây khác, đẩy nhanh quá trình thực thi Crawl4AI.
- Môi trường cô lập & phiên bền vững: Mỗi hồ sơ Scrapeless chạy trong môi trường riêng với đăng nhập liên tục và cô lập danh tính, ngăn chặn nhiễu phiên và cải thiện độ ổn định quy mô lớn.
- Quản lý dấu vân tay linh hoạt: Scrapeless có thể tạo dấu vân tay trình duyệt ngẫu nhiên hoặc sử dụng cấu hình tùy chỉnh, giúp giảm thiểu rủi ro bị phát hiện và cải thiện tỷ lệ thành công của Crawl4AI.
Bắt đầu
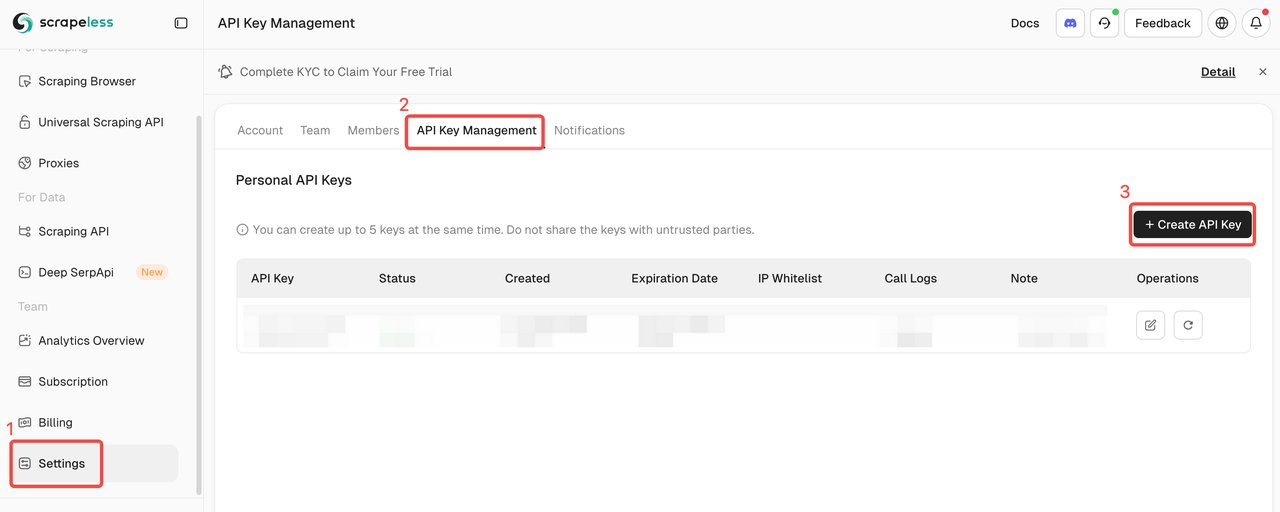
1. Lấy Khóa API Scrapeless của bạn
Đăng nhập vào Scrapeless và lấy Mã thông báo API của bạn.
2. Bắt đầu nhanh
Ví dụ dưới đây cho thấy cách kết nối Crawl4AI với Trình duyệt đám mây Scrapeless một cách nhanh chóng và dễ dàng:
Để biết thêm tính năng và hướng dẫn chi tiết, xem giới thiệu.
scrapeless_params = {
"token": "get your token from https://www.scrapeless.com",
"sessionName": "Scrapeless browser",
"sessionTTL": 1000,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url
)
)
Sau khi cấu hình, Crawl4AI kết nối với Trình duyệt đám mây Scrapeless qua chế độ CDP (Chrome DevTools Protocol), cho phép thu thập dữ liệu web mà không cần môi trường trình duyệt cục bộ. Người dùng có thể cấu hình thêm proxy, dấu vân tay, tái sử dụng phiên và các tính năng khác để đáp ứng nhu cầu của các kịch bản chống bot phức tạp và đồng thời cao.
3. Xoay Proxy Tự động Toàn cầu
Scrapeless hỗ trợ IP dân cư tại 195 quốc gia. Người dùng có thể cấu hình khu vực mục tiêu bằng cách sử dụng proxycountry, cho phép gửi yêu cầu từ các vị trí cụ thể. Các IP được tự động xoay vòng, giúp tránh bị chặn hiệu quả.
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Proxy Demo",
# Sets the target country/region for the proxy, sending requests via an IP address from that region. You can specify a country code (e.g., US for the United States, GB for the United Kingdom, ANY for any country). See country codes for all supported options."proxyCountry": "ANY",
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())
4. Dấu vân tay trình duyệt tùy chỉnh
Để mô phỏng hành vi người dùng thực, Scrapeless hỗ trợ dấu vân tay trình duyệt được tạo ngẫu nhiên và cũng cho phép các tham số dấu vân tay tùy chỉnh. Điều này giúp giảm thiểu rủi ro bị phát hiện bởi các trang web mục tiêu một cách hiệu quả.
import json
import asyncio
from urllib.parse import quote, urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
# customize browser fingerprint
fingerprint = {
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36",
"platform": "Windows",
"screen": {
"width": 1280, "height": 1024
},
"localization": {
"languages": ["zh-HK", "en-US", "en"], "timezone": "Asia/Hong_Kong",
}
}
fingerprint_json = json.dumps(fingerprint)
encoded_fingerprint = quote(fingerprint_json)
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Fingerprint Demo",
"fingerprint": encoded_fingerprint,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())
5. Tái sử dụng hồ sơ
Scrapeless gán cho mỗi hồ sơ một môi trường trình duyệt độc lập riêng, cho phép đăng nhập liên tục và cô lập danh tính. Người dùng chỉ cần cung cấp profileId để tái sử dụng một phiên trước đó.
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Profile Demo",
"profileId": "your profileId",# create profile on scrapeless
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())