Web 爬虫中的 Cloudflare 绕过
爬虫浏览器和 Cloudflare
本技术文档介绍如何使用 Scrapeless 爬虫浏览器和 Scrapeless Web Unlocker 工具来处理 Cloudflare 设置的各种安全挑战。主要功能包括绕过 Cloudflare JS 挑战、Cloudflare Turnstile 以及执行 JavaScript 渲染以访问受 Cloudflare 保护的内容。本文档将提供相关的背景知识、功能介绍、操作步骤和代码示例说明。
了解 Cloudflare 挑战和安全层
Cloudflare 是一款流行的 Web 安全和性能服务,主要保护网站免受恶意或意外流量(例如机器人和扫描程序)的攻击。为此,Cloudflare 实施了各种检测和防御机制,包括但不限于:
1. JS 挑战(JavaScript 挑战): 需要访问者的浏览器执行特定的 JavaScript 代码,以验证其是否为具有标准功能的合法浏览器环境。
2. Turnstile CAPTCHA 替代方案: 一种侵入性较小的验证机制,用于区分人类用户和机器人。
3. 浏览器指纹识别: 收集和分析浏览器和设备的技术特征(例如 User-Agent、屏幕分辨率、已安装字体、插件)以识别和跟踪访问者。
4. 速率限制: 监控和限制特定时间内来自单个来源(例如 IP 地址)的请求数量,以防止暴力破解或资源滥用。
这些安全层阻止基本的 HTTP 请求库、简单的脚本或配置不当的无头浏览器访问受 Cloudflare 保护的网站,导致验证失败和访问被拒绝。
Cloudflare JS 挑战与其他挑战的区别
Cloudflare JS 挑战的独特性在于其验证方法。它不仅要求用户完成简单的交互式任务(例如图像识别);它还要求客户端环境(浏览器)成功解析并执行 Cloudflare 生成的动态的、通常是模糊处理的 JavaScript 代码。此代码执行环境检查、计算密集型任务或其他逻辑,以验证客户端的复杂行为能力,模拟真实的浏览器。
成功通过 JS 挑战需要生成有效的清除令牌(通常以 cf_clearance cookie 的形式)。此令牌证明客户端通过了 JavaScript 执行能力验证。许多自动化工具缺乏完整的 JavaScript 执行引擎和真实的浏览器环境模拟,因此无法通过此类挑战。
使用 Scrapeless 爬虫浏览器绕过 Cloudflare JS 挑战
Scrapeless 爬虫浏览器旨在处理复杂的网站保护措施,包括 Cloudflare JS 挑战。
步骤和代码示例
环境设置
创建项目文件夹
为项目创建一个新文件夹,例如:scrapeless-bypass。
在终端中导航到该文件夹:
cd path/to/scrapeless-bypass初始化 Node.js 项目
运行以下命令创建 package.json 文件:
npm init -y安装所需的依赖项
安装 Puppeteer-core,它允许远程连接到浏览器实例:
npm install puppeteer-core如果您的系统上尚未安装 Puppeteer,请安装完整版本:
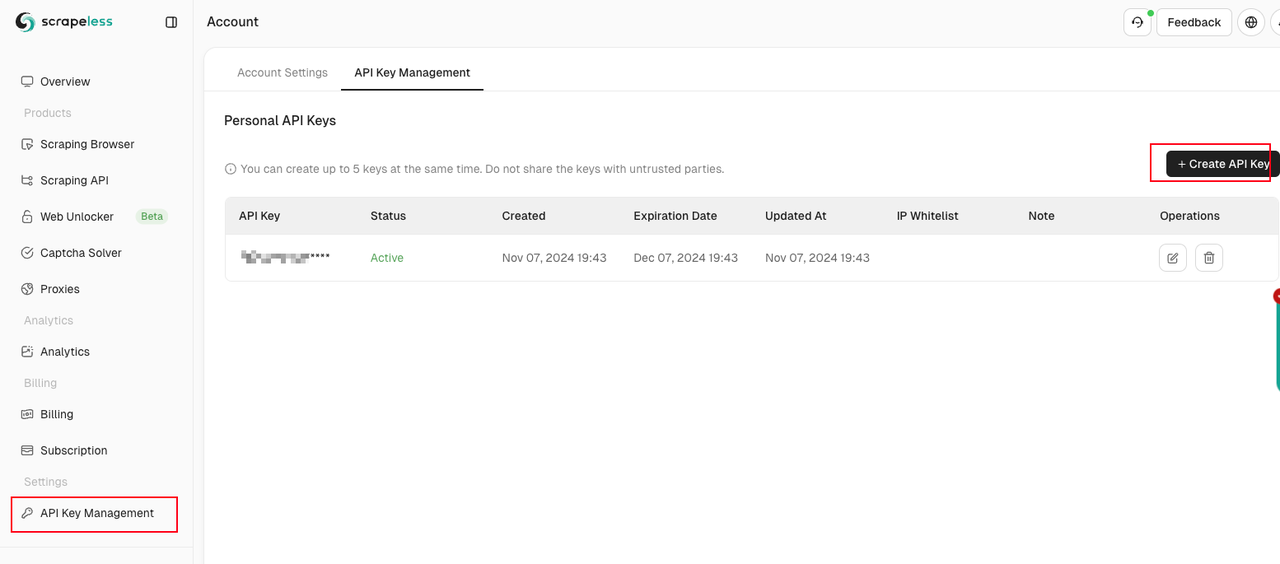
npm install puppeteer puppeteer-core获取和配置您的 Scrapeless API 密钥。
连接并确保 CAPTCHA 已成功解决
Scrapeless 在连接到浏览器以访问目标网站时会自动检测和解决 CAPTCHA。但是,我们需要确保 CAPTCHA 已成功解决。Scrapeless 爬虫浏览器使用一组强大的自定义功能扩展了标准 CDP(Chrome DevTools 协议)。可以通过检查从 CDP API 返回的结果来直接观察 CAPTCHA 解算程序的状态:
Captcha.detected: 检测到 CAPTCHACaptcha.solveFinished: CAPTCHA 成功解决Captcha.solveFailed: CAPTCHA 解决失败
import puppeteer from "puppeteer-core";
import EventEmitter from 'events';
import { Scrapeless } from '@scrapeless-ai/sdk';
const emitter = new EventEmitter();
const client = new Scrapeless({ apiKey: 'API Key' });
const { browserWSEndpoint } = client.browser.create({
sessionName: 'sdk_test',
sessionTTL: 180,
proxyCountry: 'ANY',
sessionRecording: true,
fingerprint,
});
export async function example(url) {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null
});
console.log("Verbonden met Scrapeless browser");
try {
const page = await browser.newPage();
// Listen for captcha events
console.debug("addCaptchaListener: Start listening for captcha events");
await addCaptchaListener(page);
console.log("Navigated to URL:", url);
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 30000 });
console.log("onCaptchaFinished: Waiting for captcha solving to finish...");
await onCaptchaFinished()
// Screenshot for debugging
console.debug("Taking screenshot of the final page...");
await page.screenshot({ path: 'screenshot.png', fullPage: true });
} catch (error) {
console.error(error);
} finally {
await browser.close();
console.log("Browser closed");
}
}
async function addCaptchaListener(page) {
const client = await page.createCDPSession();
client.on("Captcha.detected", (msg) => {
console.debug("Captcha.detected: ", msg);
});
client.on("Captcha.solveFinished", async (msg) => {
console.debug("Captcha.solveFinished: ", msg);
emitter.emit("Captcha.solveFinished", msg);
client.removeAllListeners()
});
}
async function onCaptchaFinished(timeout = 60_000) {
return Promise.race([
new Promise((resolve) => {
emitter.on("Captcha.solveFinished", (msg) => {
resolve(msg);
});
}),
new Promise((_, reject) => setTimeout(() => reject('Timeout'), timeout))
])
}此示例工作流程访问目标网站并通过侦听 Captcha.solveFinished CDP 事件来确认 CAPTCHA 已成功解决。最后,它捕获页面的屏幕截图以进行验证。
此示例定义了两种主要方法:
addCaptchaListener:用于侦听浏览器会话中的 CAPTCHA 事件onCaptchaFinished:用于等待直到 CAPTCHA 已解决
上述示例代码可用于侦听本文中讨论的三种常见 CAPTCHA 类型的 CDP 事件:reCAPTCHA v2、Cloudflare Turnstile 和 Cloudflare 5s 挑战。
请注意,Cloudflare 5s 挑战有些特殊。有时它不会触发实际的挑战,并且仅依靠 CDP 事件检测成功可能会导致超时。因此,在挑战之后等待页面上出现特定元素是更稳定的解决方案。
连接到 Scrapeless 无服务器 WebSocket
Scrapeless 提供 WebSocket 连接,允许 Puppeteer 直接与无头浏览器交互,从而绕过 Cloudflare 挑战。
完整的 WebSocket 连接地址:
wss://browser.scrapeless.com/api/v2/browser?token=APIKey&sessionTTL=180&proxyCountry=ANY代码示例:绕过 Cloudflare 挑战
我们只需要以下代码即可连接到 Scrapeless 的无服务器服务。
import puppeteer from 'puppeteer-core';
const API_KEY = 'your_api_key'
const host = 'wss://browser.scrapeless.com/api/v2';
const query = new URLSearchParams({
token: API_KEY,
sessionTTL: '180', // 浏览器会话的生命周期(秒)
proxyCountry: 'GB', // 代理国家/地区
proxySessionId: 'test_session_id', // 代理会话 ID 用于保持代理 IP 不变。会话时间默认为 3 分钟,基于 proxySessionDuration 设置。
proxySessionDuration: '5' // 代理会话时间,单位分钟
}).toString();
const connectionURL = `${host}/browser?${query}`;
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
});
console.log('Connected!')访问受 Cloudflare 保护的网站和屏幕截图验证
接下来,我们使用 scrapeless 无服务器 直接访问 cloudflare-challenge 测试网站 并添加屏幕截图,以便进行视觉验证。在截取屏幕截图之前,请注意您需要使用 waitForSelector 来等待页面上的元素,以确保已成功绕过 Cloudflare 挑战。
const page = await browser.newPage();
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {waitUntil: 'domcontentloaded'});
// 通过等待站点页面中的元素,确保已成功绕过 Cloudflare 挑战。
await page.waitForSelector('main.page-content .challenge-info', {timeout: 30 * 1000})
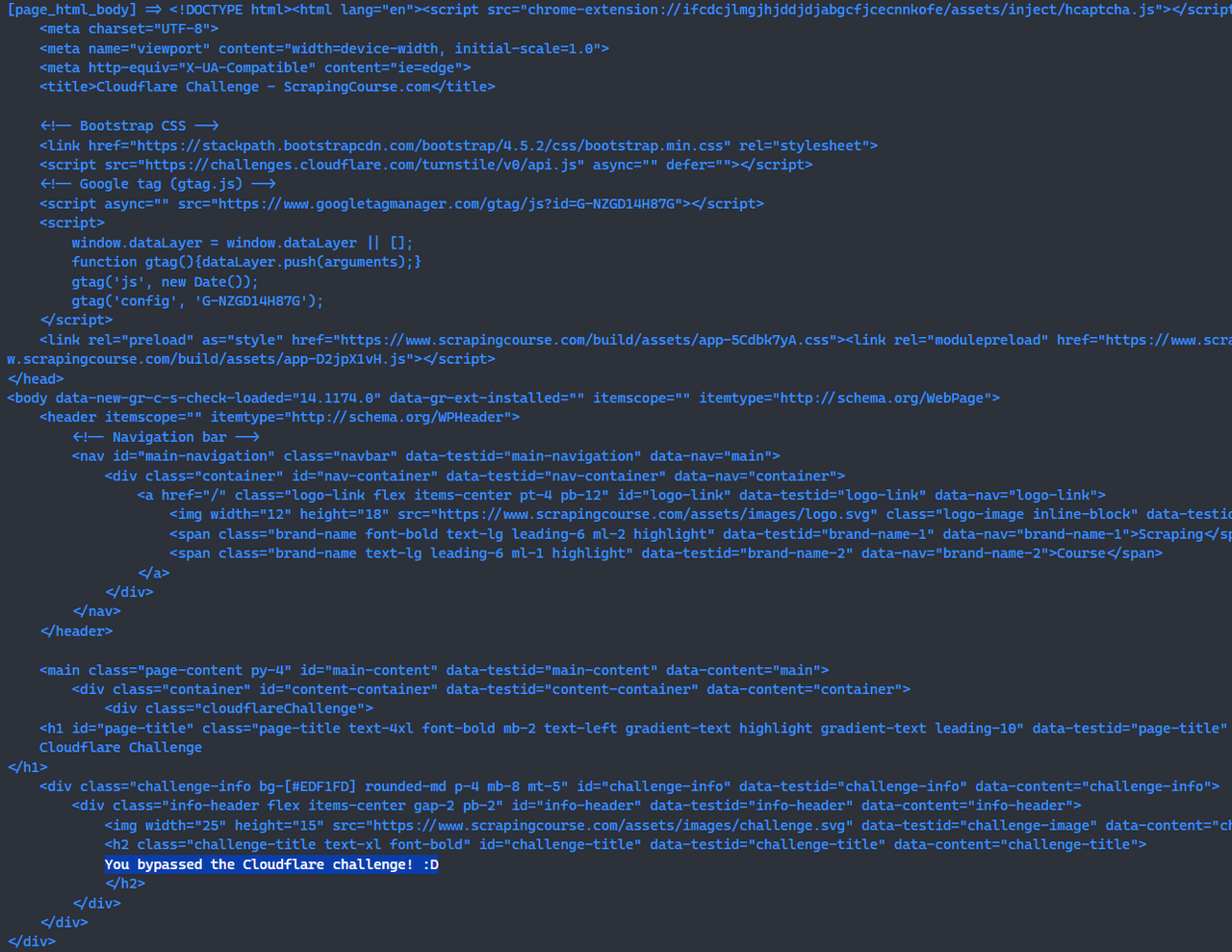
await page.screenshot({path: 'challenge-bypass.png'});此时,您已使用 Scrapeless 无服务器绕过了 Cloudflare 挑战。

获取 cf_clearance Cookie 和标头
通过 Cloudflare 挑战后,您可以从成功的页面中检索请求标头和 cf_clearance cookie。
const cookies = await browser.cookies()
const cfClearance = cookies.find(cookie => cookie.name === 'cf_clearance')?.value启用请求拦截以捕获请求标头并匹配 Cloudflare 挑战后的页面请求。
await page.setRequestInterception(true);
page.on('request', request => {
// 匹配 Cloudflare 挑战后的页面请求
if (request.url().includes('https://www.scrapingcourse.com/cloudflare-challenge') && request.headers()?.['origin']) {
const accessRequestHeaders = request.headers();
console.log('[access_request_headers] =>', accessRequestHeaders);
}
request.continue();
});使用 Scrapeless Web Unlocker 进行 JavaScript 渲染
对于核心内容依赖于客户端 JavaScript 执行才能完全加载和显示的受 Cloudflare 保护的网站,Scrapeless Web Unlocker 提供了专门的解决方案。
Scrapeless 通用 API 支持 JavaScript 渲染和动态交互,使其成为绕过 Cloudflare 的有效工具。
JavaScript 渲染
JavaScript 渲染支持处理动态加载的内容和 SPA(单页应用程序)。它支持完整的浏览器环境,处理更复杂的页面交互和渲染需求。
使用 input.jsRender.enabled=true,我们将使用浏览器进行请求
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.google.com/",
"jsRender": {
"enabled": true
}
},
"proxy": {
"country": "US"
}
}JavaScript 指令
提供广泛的 JavaScript 指令集,允许与网页进行动态交互。
这些指令支持单击元素、填充表单、提交表单或等待特定元素出现,为诸如单击“阅读更多”按钮或提交表单等任务提供灵活性。
{
"actor": "unlocker.webunlocker",
"input": {
"url": "https://example.com",
"jsRender": {
"enabled": true,
"instructions": [
{
"waitFor": [
".dynamic-content",
30000
]
// 等待元素
},
{
"click": [
"#load-more",
1000
]
// 单击元素
},
{
"fill": [
"#search-input",
"search term"
]
// 填充表单
},
{
"keyboard": [
"press",
"Enter"
]
// 模拟按键
},
{
"evaluate": "window.scrollTo(0, document.body.scrollHeight)"
// 执行自定义 JS
}
]
}
}
}挑战绕过示例
以下示例使用 axios 向 Scrapeless 的 Web Unlocker 服务发送请求。它启用 input.jsRender.enabled 并使用 input.jsRender.instructions 参数中的 waitFor 指令来等待页面上绕过 Cloudflare 挑战后的元素:
import axios from 'axios'
async function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v2/unlocker/request`;
const API_KEY = 'your_api_key'
const payload = {
actor: "unlocker.webunlocker",
proxy: {
country: "US"
},
input: {
url: "https://www.scrapingcourse.com/cloudflare-challenge",
jsRender: {
enabled: true,
instructions: [
{
waitFor: [
"main.page-content .challenge-info",
30000
]
}
]
}
}
}
try {
const response = await axios.post(url, payload, {
headers: {
'Content-Type': 'application/json',
'x-api-token': API_KEY
}
});
console.log("[page_html_body] =>", response.data);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();运行上述脚本后,您将能够在控制台中看到成功绕过 Cloudflare 挑战的页面的 HTML。