Crawl4AI
Crawl4AI is an open-source web crawling and scraping tool designed to seamlessly integrate with Large Language Models (LLMs), AI Agents, and data pipelines. It enables high-speed, real-time data extraction while remaining flexible and easy to deploy.
Key features for AI-powered web scraping include:
- Built for LLMs: Generates structured Markdown optimized for Retrieval-Augmented Generation (RAG) and fine-tuning.
- Flexible browser control: Supports session management, proxy usage, and custom hooks.
- Heuristic intelligence: Uses smart algorithms to optimize data parsing.
- Fully open-source: No API key required; deployable via Docker and cloud platforms.
Learn more in the official documentation.
Why Use Scrapeless with Crawl4AI?
Crawl4AI excels at structured web data extraction and supports LLM-driven parsing and pattern-based scraping. However, it can still face challenges when dealing with advanced anti-bot mechanisms, such as:
- Local browsers being blocked by Cloudflare, AWS WAF, or reCAPTCHA
- Performance bottlenecks during large-scale concurrent crawling, with slow browser startup
- Complex debugging processes that make issue tracking difficult
Scrapeless Cloud Browser solves these pain points perfectly:
- One-click anti-bot bypass: Automatically handles reCAPTCHA, Cloudflare Turnstile/Challenge, AWS WAF, and more. Combined with Crawl4AI’s structured extraction power, it significantly boosts success rates.
- Unlimited concurrent scaling: Launch 50–1000+ browser instances per task within seconds, removing local crawling performance limits and maximizing Crawl4AI efficiency.
- 40%–80% cost reduction: Compared to similar cloud services, total costs drop to just 20%–60%. Pay-as-you-go pricing makes it affordable even for small-scale projects.
- Visual debugging tools: Use Session Replay and Live URL Monitoring to watch Crawl4AI tasks in real time, quickly identify failure causes, and reduce debugging overhead.
- Zero-cost integration: Natively compatible with Playwright (used by Crawl4AI), requiring only one line of code to connect Crawl4AI to the cloud — no code refactoring needed.
- Edge Node Service (ENS): Multiple global nodes deliver startup speed and stability 2–3× faster than other cloud browsers, accelerating Crawl4AI execution.
- Isolated environments & persistent sessions: Each Scrapeless profile runs in its own environment with persistent login and identity isolation, preventing session interference and improving large-scale stability.
- Flexible fingerprint management: Scrapeless can generate random browser fingerprints or use custom configurations, effectively reducing detection risks and improving Crawl4AI’s success rate.
Getting Started
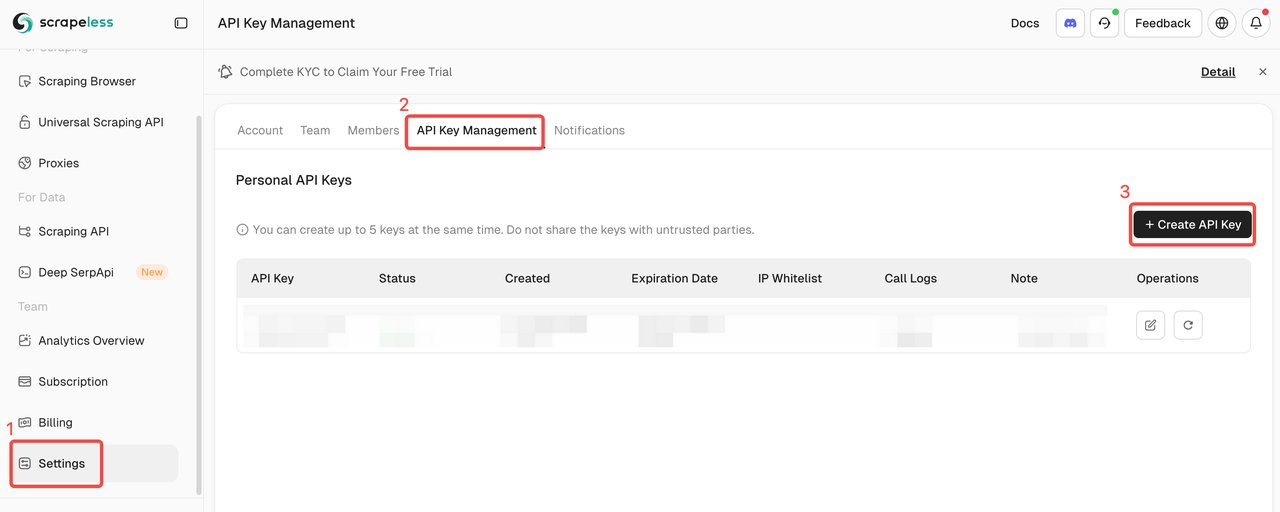
1. Get Your Scrapeless API Key
Log in to Scrapeless and get your API Token.
2. Quick Start
The example below shows how to quickly and easily connect Crawl4AI to the Scrapeless Cloud Browser:
For more features and detailed instructions, see the introduction.
scrapeless_params = {
"token": "get your token from https://www.scrapeless.com",
"sessionName": "Scrapeless browser",
"sessionTTL": 1000,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"
AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url
)
)
After configuration, Crawl4AI connects to the Scrapeless Cloud Browser via CDP (Chrome DevTools Protocol) mode, enabling web scraping without a local browser environment. Users can further configure proxies, fingerprints, session reuse, and other features to meet the demands of high-concurrency and complex anti-bot scenarios.
3. Global Automatic Proxy Rotation
Scrapeless supports residential IPs across 195 countries. Users can configure the target region using proxycountry, enabling requests to be sent from specific locations. IPs are automatically rotated, effectively avoiding blocks.
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Proxy Demo",
# Sets the target country/region for the proxy, sending requests via an IP address from that region. You can specify a country code (e.g., US for the United States, GB for the United Kingdom, ANY for any country). See country codes for all supported options."proxyCountry": "ANY",
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())
4. Custom Browser Fingerprints
To mimic real user behavior, Scrapeless supports randomly generated browser fingerprints and also allows custom fingerprint parameters. This effectively reduces the risk of being detected by target websites.
import json
import asyncio
from urllib.parse import quote, urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
# customize browser fingerprint
fingerprint = {
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.1.2.3 Safari/537.36",
"platform": "Windows",
"screen": {
"width": 1280, "height": 1024
},
"localization": {
"languages": ["zh-HK", "en-US", "en"], "timezone": "Asia/Hong_Kong",
}
}
fingerprint_json = json.dumps(fingerprint)
encoded_fingerprint = quote(fingerprint_json)
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Fingerprint Demo",
"fingerprint": encoded_fingerprint,
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com/en",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())
5. Profile Reuse
Scrapeless assigns each profile its own independent browser environment, enabling persistent logins and identity isolation. Users can simply provide the profileId to reuse a previous session.
import asyncio
from urllib.parse import urlencode
from crawl4ai import CrawlerRunConfig, BrowserConfig, AsyncWebCrawler
async def main():
scrapeless_params = {
"token": "your token",
"sessionTTL": 1000,
"sessionName": "Profile Demo",
"profileId": "your profileId",# create profile on scrapeless
}
query_string = urlencode(scrapeless_params)
scrapeless_connection_url = f"wss://browser.scrapeless.com/api/v2/browser?{query_string}"async with AsyncWebCrawler(
config=BrowserConfig(
headless=False,
browser_mode="cdp",
cdp_url=scrapeless_connection_url,
)
) as crawler:
result = await crawler.arun(
url="https://www.scrapeless.com",
config=CrawlerRunConfig(
wait_for="css:.content",
scan_full_page=True,
),
)
print("-" * 20)
print(f'Status Code: {result.status_code}')
print("-" * 20)
print(f'Title: {result.metadata["title"]}')
print(f'Description: {result.metadata["description"]}')
print("-" * 20)
asyncio.run(main())