Browser MCP
Scrapeless Browser MCP Server seamlessly connects models like ChatGPT, Claude, and tools like Cursor and Windsurf to a wide range of external capabilities, including:
- Browser automation for page-level navigation and interaction
- Scrape dynamic, JS-heavy sites—export as HTML, Markdown, or screenshots
| MCP Type | Tech Stack | Advantages | Primary Ecosystem | Best For |
|---|---|---|---|---|
| Chrome DevTools MCP | Node.js / Puppeteer | Official standard, robust, deep performance analysis tools. | Broad (Gemini, Copilot, Cursor) | CI/CD automation, cross-IDE workflows, and in-depth performance audits. |
| Playwright MCP | Node.js / Playwright | Uses accessibility tree instead of pixels; deterministic and LLM-friendly without vision. | Broad (VS Code, Copilot) | Reliable, structured automation that is less prone to breaking from minor UI changes. |
| Scrapeless Browser MCP | Cloud Service | Zero local setup, scalable cloud browsers, handles complex sites and anti-bot measures. | API-driven (Any client) | Large-scale, parallel automation tasks, and interacting with websites that have strong bot detection. |
Supported MCP Tools
| Name | Description |
|---|---|
| browser_create | Create or reuse a cloud browser session using Scrapeless. |
| browser_close | Closes the current session by disconnecting the cloud browser. |
| browser_goto | Navigate browser to a specified URL. |
| browser_go_back | Go back one step in browser history. |
| browser_go_forward | Go forward one step in browser history. |
| browser_click | Click a specific element on the page. |
| browser_type | Type text into a specified input field. |
| browser_press_key | Simulate a key press. |
| browser_wait_for | Wait for a specific page element to appear. |
| browser_wait | Pause execution for a fixed duration. |
| browser_screenshot | Capture a screenshot of the current page. |
| browser_get_html | Get the full HTML of the current page. |
| browser_get_text | Get all visible text from the current page. |
| browser_scroll | Scroll to the bottom of the page. |
| browser_scroll_to | Scroll a specific element into view. |
| scrape_html | Scrape a URL and return its full HTML content. |
| scrape_markdown | Scrape a URL and return its content as Markdown. |
| scrape_screenshot | Capture a high-quality screenshot of any webpage. |
Getting Started
Get Your Scrapeless API Key
Log in to Scrapeless and get your API Token.

Configure Your MCP Client
Scrapeless MCP Server supports both Stdio and Streamable HTTP transport modes.
🖥️ Stdio (Local Execution)
{
"mcpServers": {
"Scrapeless MCP Server": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}
🌐 Streamable HTTP (Hosted API Mode)
{
"mcpServers": {
"Scrapeless MCP Server": {
"type": "streamable-http",
"url": "https://api.scrapeless.com/mcp",
"headers": {
"x-api-token": "YOUR_SCRAPELESS_KEY"
},
"disabled": false,
"alwaysAllow": []
}
}
}
Advanced Options
Customize browser session behavior with optional parameters. These can be set via environment variables (for Stdio) or HTTP headers (for Streamable HTTP):
| Stdio (Env Var) | Streamable HTTP (HTTP Header) | Description |
|---|---|---|
| BROWSER_PROFILE_ID | x-browser-profile-id | Specifies a reusable browser profile ID for session continuity. |
| BROWSER_PROFILE_PERSIST | x-browser-profile-persist | Enables persistent storage for cookies, local storage, etc. |
| BROWSER_SESSION_TTL | x-browser-session-ttl | Defines the maximum session timeout in seconds. The session will automatically expire after this duration of inactivity. |
Use Cases
Web Scraping & Data Collection
- E-commerce Monitoring: Automatically visit product pages to collect prices, stock status, and descriptions.
- Market Research: Batch scrape news, reviews, or company pages for analysis and comparison.
- Content Aggregation: Extract page content, posts, and comments for centralized collection.
- Lead Generation: Gather contact information and company details from corporate websites or directories.
Testing & Quality Assurance
- Function Verification: Use clicks, typing, and element waits to ensure pages behave as expected.
- User Journey Testing: Simulate real user interactions (typing, clicking, scrolling) to validate workflows.
- Regression Testing Support: Capture screenshots of key pages and compare to detect UI or content changes.
Task & Workflow Automation
- Form Filling: Automatically complete and submit web forms (e.g., registrations, surveys).
- Data Capture & Report Generation: Periodically extract page data and save as HTML or screenshots for analysis.
- Simple Administrative Tasks: Automate repetitive backend or web-based operations using simulated clicks and typing.
Showcase
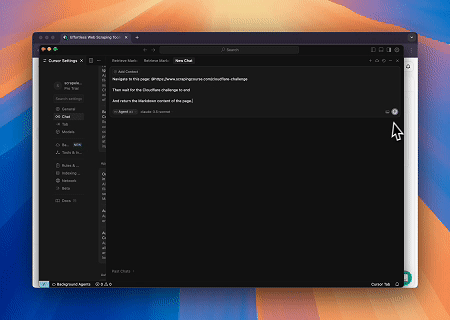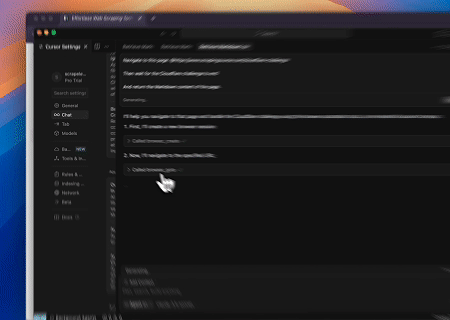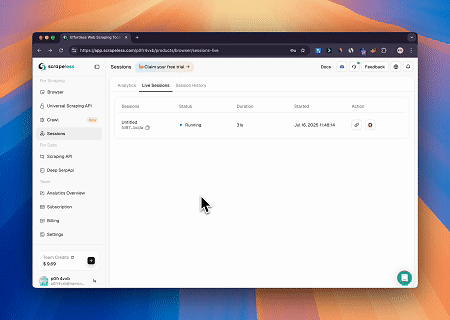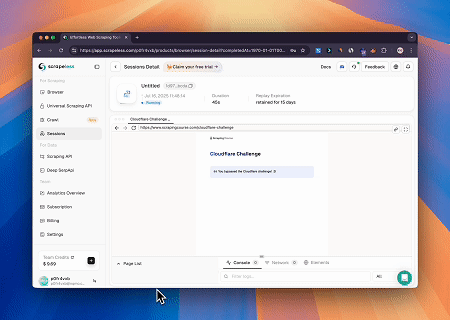
Case 1: Web Interaction and Data Extraction Automation with Claude
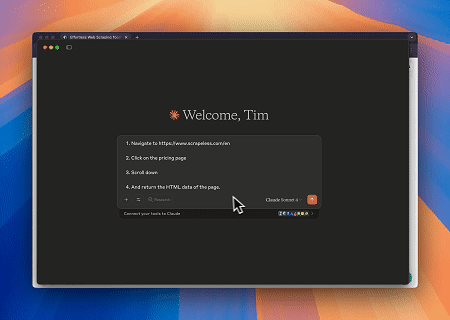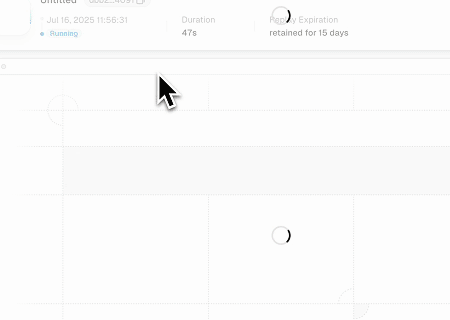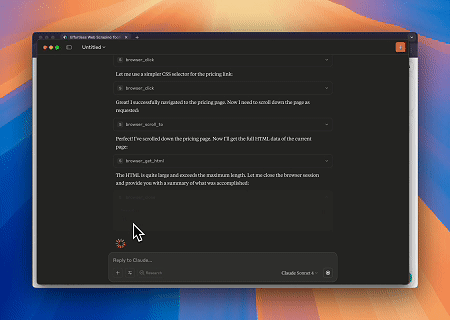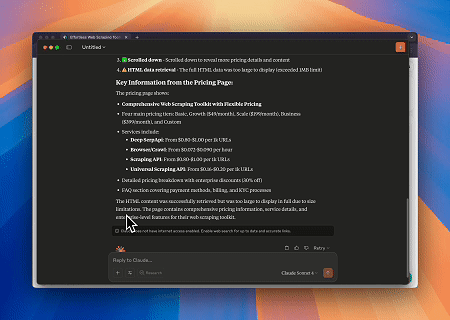
Using Browser MCP Server, Claude can perform complex web operations—such as navigation, clicking, scrolling, and data scraping—through conversational commands, with real-time execution preview via live sessions.
Case 2: Bypassing Cloudflare to Retrieve Target Page Content
Using the Browser MCP Server, Cloudflare-protected pages are automatically accessed, and upon completion, the page content is extracted and returned in Markdown format.
One Cloud Browser, Infinite Integrations
Chrome DevTools MCP, Playwright MCP, and Scrapeless Browser MCP — share one foundation: they all connect to the Scrapeless Cloud Browser.
Unlike traditional local browser automation, Scrapeless Browser runs entirely in the ****cloud, providing unmatched flexibility and scalability for developers and AI agents.
Here’s what makes it truly powerful:
- Seamless Integration: Fully compatible with Puppeteer, Playwright, and CDP, allowing effortless migration from existing projects with a single line of code.
- Global IP Coverage: Access to residential, ISP, and unlimited IP pools across 195+ countries, at a transparent and cost-effective rate ($0.6–1.8/GB). Perfect for large-scale web data automation.
- Isolated Profiles: Each task runs in a dedicated, persistent environment, ensuring session isolation, multi-account management, and long-term stability.
- Unlimited concurrent scaling: Instantly launch 50–1000+ browser instances with auto-scaling infrastructure — no server setup, no performance bottleneck.
- Edge Nodes Worldwide: Deploy on multiple global nodes for ultra-low latency and 2–3× faster startup than other cloud browsers.
- Anti-Detection: Built-in solutions for reCAPTCHA, Cloudflare Turnstile, and AWS WAF, ensuring uninterrupted automation even under strict protection layers.
- Visual Debugging: Achieve human-machine interactive debugging and real-time proxy traffic monitoring via Live View. Replay sessions page-by-page through Session Recordings to quickly identify issues and optimize operations.
Integrations
Claude Desktop
- Open Claude Desktop
- Navigate to:
Settings→Tools→MCP Servers - Click “Add MCP Server”
- Paste either the
StdioorStreamable HTTPconfig above - Save and enable the server
- Claude will now be able to issue web queries, extract content, and interact with pages using Scrapeless
Cursor IDE
- Open Cursor
- Press
Cmd + Shift + Pand search for:Configure MCP Servers - Add the Scrapeless MCP config using the format above
- Save the file and restart Cursor (if needed)
- Now you can ask Cursor things like:
"Search StackOverflow for a solution to this error""Scrape the HTML from this page"
- And it will use Scrapeless in the background.